Here’s a headshot of me! Putting it out there in case someone needs to grab one for a talk/poster/article or whatnot. These photos were taken by Ceilidh Kehoe at the UVM Larner College of Medicine’s Office of Medical Communications and can be used for promotional material.
Here’s the full res version that it was cropped from:
WordPress (this blog) compresses images, so here’s a link to the uncompressed, uncropped images:
MyChart is a handy tool to access your personal health information, request medication refills, message your medical team, and more. Many hospital systems throughout the US use their institution’s MyChart messaging platform to invite patients to participate in research studies. In late 2025, the UVM Medical Center’s Epic Electronic Medical Record system was upgraded and now supports the sending of messages to patients with opportunities to participate in clinical studies.
How can I opt out of receiving MyChart recruitment messages?
Opting out is easy! Please note that opting out only affects recruitment messages that you get through MyChart.
Opting out from the MyChart website
Go to https://mychart.uvmhealth.org and log in with your personal account information. When you are in your account’s home page, click the menu button (top left button with three horizontal lines) and scroll down to “Research Studies” under “Resources”. Select “Do Not Contact”.
Opting out from the MyChart app on iPhone or Android
Open up the MyChart app on your device and hit the menu button (three horizontal lines near the top) and scroll down to “Research Studies” under “Resources”. Select “Do Not Contact”.
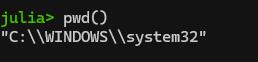
One step will be changing your working directory to the place where you actually want to be working. See your current working directory with “pwd()“. Note: if you get a message saying “pwd (generic function with 1 method)”, you entered “pwd” and not “pwd()”.
Anyway, here’s what I see:
What’s up with the double slashes in Windows directories? Windows is unique among OSes in that it uses backslashes (\) and not forward slashes (/) in its file structure. It turns out that the backward slash is also special character in coding so you have to do two slashes for “normal” slashes as a translation in a lot of coding programs (details here). If you want to change your directory in Windows, you’ll need to deal with single to double backslashes conversion by either (1) adding a second backslash everywhere it shows up in a directory, or (2) declare the string to be raw as is described here. See more on the second, easier option below.
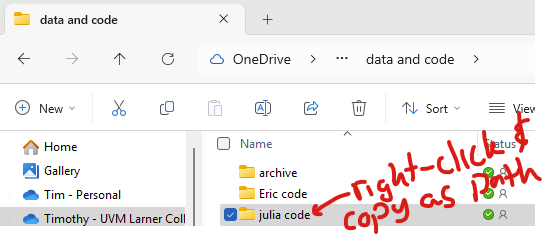
You can change the directory in Julia with “cd([your directory])“. In Windows explorer, you can copy the path by right-clicking on the desired folder and clicking “copy as path”.
So, to change your directory in windows, you need to deal with how Julia handles backslashes. Adding “raw” before the string of the directory is simpler. The following two are equivalent:
The second allows you to simply paste the directory from Windows Explorer. So, use raw before your directory string! I don’t know if people will have this problem with other operating systems, I’m guessing not.
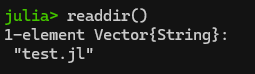
You can view the contents of your working directory (e.g., like “ls” or “dir”) with “readdir()“. In this example, I have already used cd() to change my pwd() to the folder that has a Julia script in it:
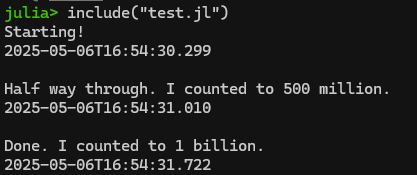
Hey! It’s my “count to a billion” code from part 1. Since it’s in my current directory, I can load it and run it using the include() command as follows:
include("test.jl")
This is actually quite a helpful command if you are writing your script in Notepad++ like we covered in Part 1. Rather than copying/pasting the contents of your script from Notepad++ into Julia/REPL, you can simply do your editing in Notepad++, save the updated script, and then re-run it using include(filename.jl)! A bit less clunky.
Importing files from other statistical packages (SAS’s sas7bdat, Stata’s .dta) using TidierFiles
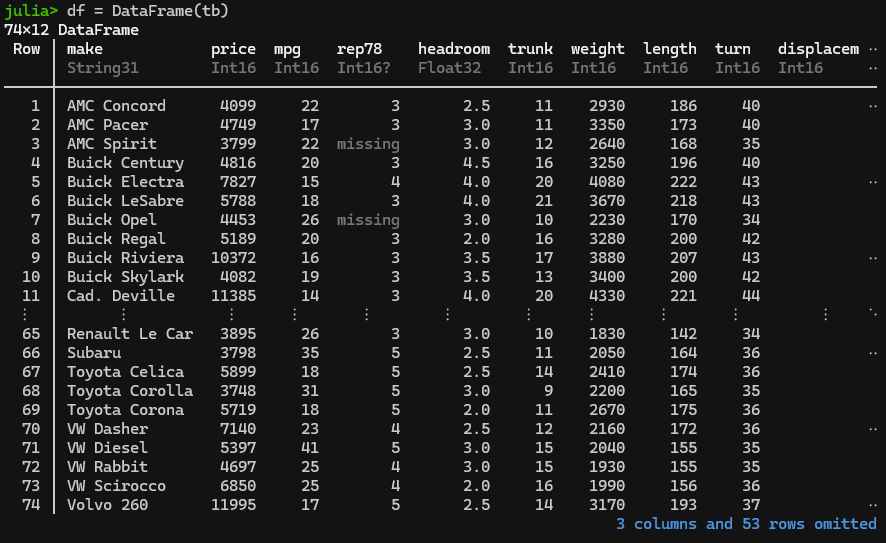
As discussed in part 1, Tidier is a meta-package that includes a ton of sub-packages in an attempt to create Tidyverse in Julia. One of Tidier’s included packages is the TidierFiles package, which reads and writes all sorts of stuff. Note: You load all Tidier packages, including TidierFiles, when you load Tidier itself. TidierFiles uses Julia’s revered DataFrame package, FYI. You’ll see “df” to name imported data sitting in a dataframe.
Step 1: Installing Tidier (and with it, TidierFiles) and DataFrame
In the package manager (hit “]” to enter), type “add Tidier”. After they install, hit backspace to get back to Julia’s REPL. Alternatively, you can run the following in the REPL or in a script to install Tidier:
using Pkg # need to remember to load Pkg itself!!
Pkg.add("Tidier") # This loads lots, including TiderFiles and DataFrame
Pkg.status() # see that it installed.
using Tidier # load tidier
# type ? and "Tidier" to see all of the packages that come with it.
# type ? and "Tidier.TidierFiles" to read about that specific package.
Step 2: Importing SAS, Stata, CSV and other files
Importing SAS: Now let’s download the airline.sas7bdat dataset from here: https://www.principlesofeconometrics.com/sas.htm — save it to your pwd(). The following command (1) uses Tidier’s TidierFiles to import the airline.sas7bdat as a DataFrame called “df” then (2) shows that it loaded correctly using varinfo().
Note: You can opt to use “read_file” instead of “read_sas” and let TidierFiles figure out what type of file it is. In 2025, this gives an error if you are trying to automate the download using a string, so better to use the “read_sas” command here.
using Tidier # this loads TidierFiles
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir() # the airline file should be in the pwd()
# the following saves the sas file as a dataframe called "df1"
df1 = read_sas("airline.sas7bdat")
# see that it loaded as a dataframe:
varinfo()
# fin
In theory, you should also be able to load the above file directly from the web, but I’m getting an IO error doing that. I’ll come back and try to debug later. This should be the correct code, I’m not sure why it’s not working.
using Tidier
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
df2 = read_sas("http://www.principlesofeconometrics.com/sas/airline.sas7bdat")
# see that it loaded as a dataframe:
varinfo()
# fin
Alternatively, you can instead use Julia to download a file to your pwd() in a script. Let’s say you want to download the andy.sas7bdat file and save it to the pwd(). the Downloads package can help with that. Install it with “]” and “add Downloads” or “using Pkg” and “Pkg.add(“Downloads”)”.
using Tidier
using Downloads
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
# specify the URL
url = "http://www.principlesofeconometrics.com/sas/andy.sas7bdat"
# Specify the destination, but need to explicitly name the file
# so grab the filename from the end of the URL and list it
# along with the pwd using the joinpath command
filename = split(url,"/") |> last
dest = joinpath(pwd(), filename)
Downloads.download(url, dest)
# see that the file is downloaded in your pwd()
readdir()
# Now use the above script to import the andy file, using the
# captured filename string to automate the import
df3 = read_sas(filename)
# see that it loaded as a dataframe:
varinfo()
# fin
Importing Stata: This is essentially identical to importing a SAS file, but use the “read_dta” command in place of “read_sas”. If you had the auto.dta file in your working directory, this is how you’d import it.
using Tidier
using Downloads
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
df4 = read_dta("auto.dta")
# see that it loaded as a dataframe:
varinfo()
# fin
using Tidier
using Downloads
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
# specify the URL
url = "https://www.stata-press.com/data/r17/auto.dta"
# Specify the destination, but need to explicitly name the file
# so grab the filename from the end of the URL and list it
# along with the pwd using the joinpath command
filename = split(url,"/") |> last
dest = joinpath(pwd(), filename)
Downloads.download(url, dest)
# see that the file is downloaded in your pwd()
readdir()
# now import that file as a dataframe:
df5 = read_dta(filename)
# see that it loaded as a dataframe:
varinfo()
# fin
Here you go!
Importing CSV and other filetypes – TidierFiles will import “csv”, “tsv”, “xlsx”, “delim”, “table”, “fwf”, “sav”, “sas”, “dta”, “arrow”, “parquet”, “rdata”, “rds, and Google sheets, you just need to select the correct command to do so (see details here) to replace “read_sas” and “read_dta” above.
Step 3: Merging DataFrames together
We’ll use NHANES data (saved as sas7bdat) and merge on SEQN, aka a unique identifier. The following script downloads the DEMO file and a cholesterol file, and saves them in DataFrames called df_demo and df_trigly
using Tidier
using Downloads
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
# Demo file
url = "https://wwwn.cdc.gov/Nchs/Data/Nhanes/Public/2013/DataFiles/DEMO_H.xpt"
filename = split(url, "/") |> last
dest = joinpath(pwd(), filename)
Downloads.download(url, dest)
readdir()
df_demo=read_sas(filename)
# Cholesterol file
url = "https://wwwn.cdc.gov/Nchs/Data/Nhanes/Public/2013/DataFiles/TRIGLY_H.xpt"
filename = split(url, "/") |> last
dest = joinpath(pwd(), filename)
Downloads.download(url, dest)
readdir()
df_chol=read_sas(filename)
# look at dataframes and strings loaded:
varinfo()
# fin
Now, let’s merge/join the df_demo and df_chol dataframes together and save it as a dataframe called df_merge. This will use TidierData’s join function, you can read about here. There are a bunch of different joins, we’ll be doing a full_join which will preserve all rows without dropping any for missing. Read about joins (“merge”) here. Of note, the join command as implemented in TidierData will infer the matching variable based upon identical columns in the two datasets. Continuing with the prior script:
df_merge = @full_join(df_demo, df_chol)
Combined code:
using Tidier
using Downloads
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
# Demo file
url = "https://wwwn.cdc.gov/Nchs/Data/Nhanes/Public/2013/DataFiles/DEMO_H.xpt"
filename = split(url, "/") |> last
dest = joinpath(pwd(), filename)
Downloads.download(url, dest)
readdir()
df_demo=read_sas(filename)
# Cholesterol file
url = "https://wwwn.cdc.gov/Nchs/Data/Nhanes/Public/2013/DataFiles/TRIGLY_H.xpt"
filename = split(url, "/") |> last
dest = joinpath(pwd(), filename)
Downloads.download(url, dest)
readdir()
df_chol=read_sas(filename)
# join/merge datasets, save as "df_merge" dataframe
df_merge = @full_join(df_demo, df_chol)
# look at dataframes that are there:
varinfo()
# fin
Exporting data
You can export your work using TidierData, just use “write_sas”, “write_dta”, “write_csv” or whatever you want. Details are here. For example, you can append the following to the end of the prior code and save the df_merge dataframe as a CSV file in your pwd(), including the column names as the first row.:
write_csv(df_merge, "NHANES_merged.csv", col_names=true)
# fin
Saving your work in Julia’s JLD2 format and then later loading it
The JLD2 file format seems to be designed to be compatible with future changes in Julia. See details here. Install it in the Pkg interface (hit “]”) then “add JLD2” or “using Pkg” and “Pkg.add(“JLD2″)”. You can save things in your memory (type “varinfo()” to see what’s loaded). For example, you can save the df_merge from 2 sections above with:
using JLD2
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
@save "mydataframe.jld2" df_merge
# look at files in pwd()
readdir()
# fin
I haven’t quite found an elegant way to reload JLD2 with Tidier, it instead uses DataFrames (which is actually included in Tidier but doesn’t correctly work with this). You’ll need to separately install DataFrames in the Pkg interface (hit “]” and type “add DataFrames” or in REML type “using Pkg” and “Pkg.add(“DataFrames”)
# close and reopen Julia, load JLD2 and DataFrames
using JLD2
using DataFrames
# set pwd() with cd(), confirm you did it correctly with pwd(), then read the pwd() contents with readdir()
cd(raw"C:\YOUR DIRECTORY")
pwd()
readdir()
# load the dataframe as df_merge.
@load "mydataframe.jld2" df_merge
# look at dataframes and strings loaded:
varinfo()
# fin
Viewing your data in the browser
One great Stata feature is “browse”, allowing you to look at all of the data. The “BrowseTables” package allows you to do something similar in Julia’s interface and (more importantly) a browser window. We will demonstrate this using the merged NHANES dataset above.
Jump to the pkg interface (hit “]”) and type “add BrowseTables” or add in REPL with “using Pkg” and “Pkg.add(“BrowseTables”) then the following:
using BrowseTables
# view 'whatever fits' in the julia terminal:
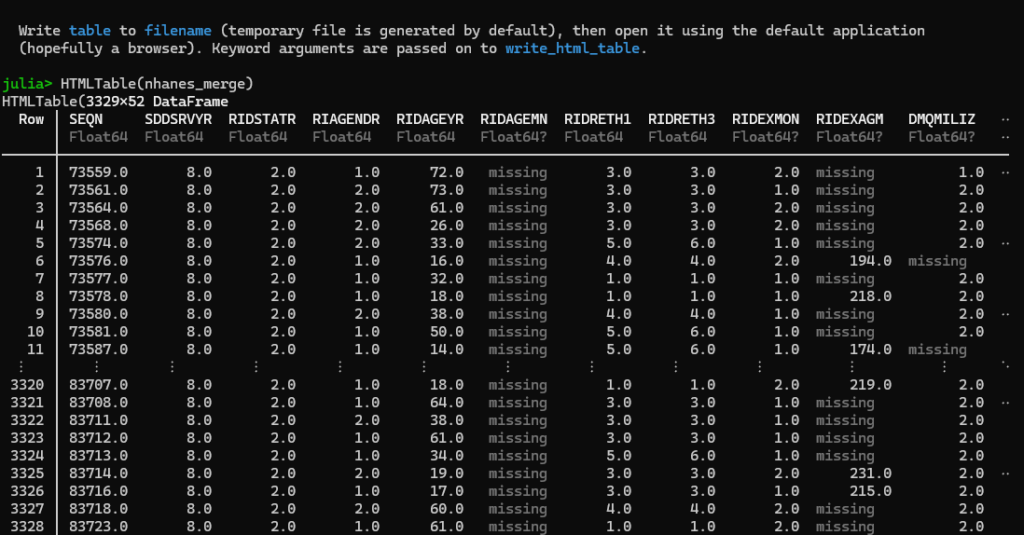
HTMLTable(df_merge)
# open up the nhanes_merge example from above in a browser:
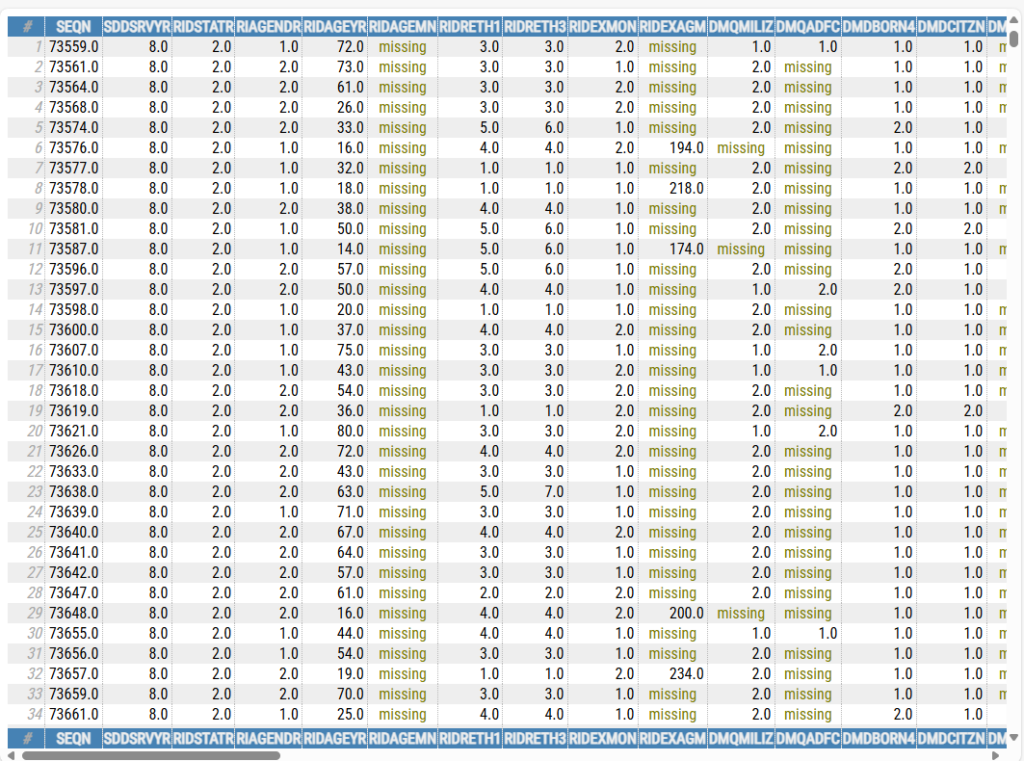
open_html_table(df_merge)
# fin
The first command, HTMLTable(df_merge), will show output in the Julia browser, truncating the columns and rows so that it fits like such:
The second command, open_html_table(df_merge), will open the entire dataset in your default browser, like so:
Stata’s ‘browse’ feature is nice in that it allows you to browse subsets of data, e.g., ‘browse if sex==”M”‘ would show data for just males. I’ll play around with this a bit more and see if there’s a simple way to subset the rendered tables to just a sample of the data.
I’m a big fan of Stata because of its simplicity and excellent documentation. I have a lot of colleagues that use R and I see why they like it, but I’m not a fan of the R syntax. I’ve played with Python and liked the syntax quite a bit but found simply installing Python and its packages to be really annoying on Windows.
The Julia language seems to have some of the nice features of R (e.g., arrays start at 1, Tidyverse-like packages, ggplot2 was rewritten in Julia) and syntax similar to Python. Julia seems to have a unique(?) feature called “broadcasting” (with shorthand being just a dot or “.”) that allows you to run commands by row. The help files seem okay, though pretty brief. Julia users aren’t typically huge jerks on online forums. I’ve read online that the speed of Julia is very attractive to R users (but I do epidemiology work in ‘relatively’ small datasets, e.g., <1 million observations, so speed of my statistical packages doesn't really make a difference in my analyses). It is similar to Stata in that missing values are treated as positive infinity. Unlike Stata, it'll use all available CPU cores in the base version (Stata only uses a single core unless you pay for a more expensive version). Finally, Julia seems to be pretty well-developed for AI/ML (as are R and Python), which is something that Stata leaves to be desired.
My main reservation about Julia is that it’s relatively new since it was only started ~13 years ago (it’s currently 2025) so it’s not going to have every package or instructional post under the sun. It’s old enough that I expect the language to be reasonably well-developed though. I’m also not a huge fan of capital letters in coding since I’m used to Stata and everything in Stata is lower case. That’s DEFINITELY not the case in Julia, and Julia is not at all forgiving if you type “using pkg” instead of “using Pkg”. But I thought I’d give it a go!
To the point of Tidyverse, my perspective is that much of the rise of R’s popularity is in the development and uptake of Tidyverse. Tidyverse is a meta-package that brings together a bunch of individual packages that simplify data analysis. Core to Tidyverse is the concept of “tidy data”, meaning that:
Each variable is a column; each column is a variable.
Each observation is a row; each row is an observation.
Each value is a cell; each cell is a single value.
…for Stata users, that should sound familiar since it’s the exact data structure that Stata uses. Only columns are called “variables” and rows are called “observations”. Conceptually, tidy data and the Tidyverse makes R run like Stata. For Julia, there is an implementation of the Tidyverse called Tidier that started ~2 years ago (it’s 2025). Like Tidyverse, Tidier is a meta-package including lots of subpackages:
TidierData – For data manipulation, like R’s dplyr and tidyr
TidierPlots – For figures, an R implementation of ggplot2
TidierFiles – For reading and writing different filetypes, like R’s haven and readr
TidierCats– For managing categorical data, like forcats
TidierDates – For managing dates/time, like lubridate
Unlike Stata, Julia is intended to have an infinite amount of “datasets” open at once, some can just be a single string, some can be a vector of data, some can be a full dataframe. However, Tidier is designed to function on only a single dataframe so if needing to include something from a “dataset” outside of the current dataframe, you need to precede the Tidier command with @eval and use a dollar sign in front of whatever the non-current-dataframe thing is. This is called interpolating, and details are here.
There aren’t many drawbacks to using Tidier that I can find, other than it being pretty new and it taking about 15-30 seconds to load the first time you load (“using”) it in a Julia session.
This series of posts documents my foray into the Julia language, being an epidemiology-focused user of Stata on Windows, with an emphasis on using Tidier. Note that Mac and Linux users can probably follow along without any problems, though the installation might be slightly different.
Things that annoy me about Julia
As I’m putting these pages together, I’m coming back to document what annoys me about Julia. Here’s an incomplete list:
Lack of forgiveness with capitalization. I’m sorry that I typed “pkg” instead of “Pkg”. Cmon though, can you let it slide? Or at least let me know that it’s a capitalization problem?
Pkg isn’t auto-loaded with Julia. C’mon…
Strings with backslashes or dollarsigns ($) and probably other characters will confuse Julia. The simple workaround is to smush ‘raw’ before the opening quote of these strings, e.g., raw”$50,000″
Sorting functions appear to sort by capital letters first, so “Zebra” would be sorted to be above “apple”. The workaround is to generate a lowercase column and sort on that. It’s clunky.
Slowness with loading packages the first time (in 2025). Tidier takes 30 seconds to load, and that’s not unique to Tidier. Yes, Julia is reported to be faster than R, but it doesn’t seem zippy when you are loading things.
Needing to manually load packages before using them. It would be nice for Julia to load packages on the fly when called the first time.
No way to ‘reset’ Julia like the ‘clear all’ command does to Stata. The current workaround is to close down Julia and open it up fresh.
No ‘cheat sheets’ for Julia packages (in 2025) like the awesome ones that have been written for Stata and R. There is a nice ‘general’ Julia cheat sheet though.
Installing Julia on Windows 11
Installing it from the command line prompt is incredibly simple. It automatically sets the PATH and whatnot. Steps: Hit win key + R to open the run prompt, then type “cmd” without quotes to open the command line in Windows (or just hit the start button and type “cmd” and click on “command prompt”), and drop the prompt listed here: https://julialang.org/install/
You can also manually install from the Julia Downloads page, but I would honestly follow the guidance on the install page above and do the command line prompt install. But here’s the Downloads page in case you need it: https://julialang.org/downloads/
The Julia download page also lists a portable version of Julia that you can run off a thumbdrive or as a folder on your desktop without needing to formally install it!: https://julialang.org/downloads/ (I’d get the 64 bit version, unlikely that you’ll run into a 32 bit windows PC these days. You can check your Windows version in cmd by entering “wmic os get osarchitecture”.) You just unzip the folder where you want it. You can run Julia by clicking “bin\julia.exe”.It takes about 30 seconds to open, but it works!
Running Julia on Windows 11
There are a few ways to run Julia. Since I’m just starting out, I’ll be using Option 1, which is a lot simpler.
Option 1 – Write Julia’s *.jl scripts in Notepad++ and run by copying/pasting them into Julia running in the Windows Terminal — aka the ‘low tech’ way
I’m a HUGE fan of Notepad++ as a text editor, and it works very well to write Julia scripts. (Notepad++ is for Windows only. If you are on MacOS or Linux, you might want to try Sublime Text Editor instead.) You’ll want to get the markup to reflect the Julia language. Steps:
In Notepad++, click Language –> User defined language –> Define your language… and then import the XML file.
To test it out, select Julia markup from the language list (Language –> way below the alphabetized list click “Julia”).
FYI, there is a portable version of Notepad++, so you can install it from your thumbdrive or local folder without having to install it. This would match a portable version of Julia. Details: https://portableapps.com/apps/development/notepadpp_portable
Now make a new script and save it as a Julia script file with the extension “*.jl” (that’s a J and an L). When you save with that file extension, Notepad++ automatically knows it’s for the Julia language and will apply your downloaded Julia markup.
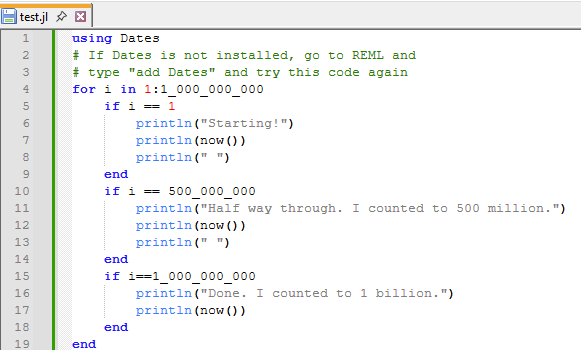
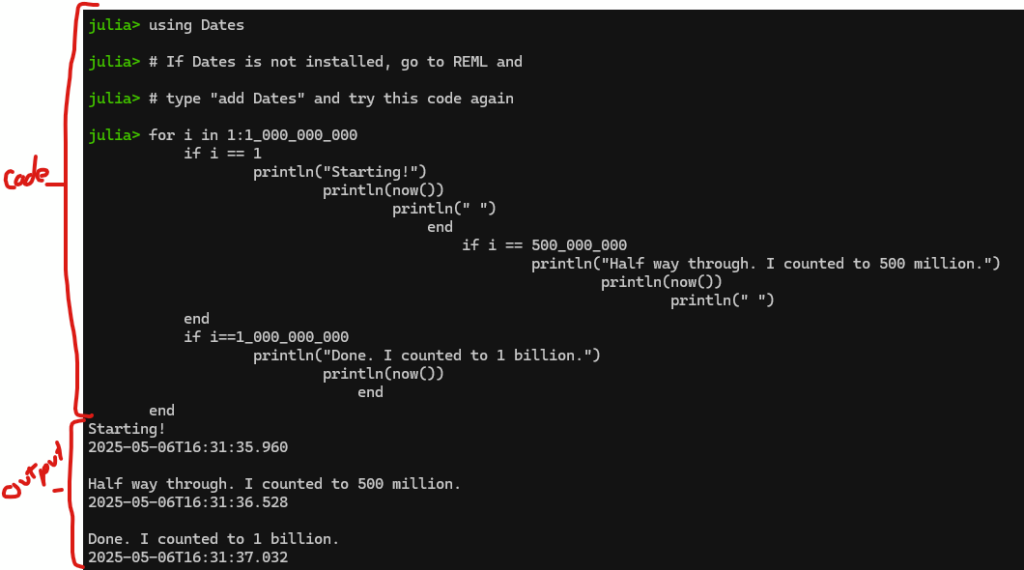
Here’s an example program. I adapted an example counter to 1 billion from section 2.1 of this great Julia Primer from Bartlomiej Lukaszuk: Romeo and Julia, where Romeo is Basic Statistics. Note that you can add an underline in large numbers to make them a bit more readable, so “1000000000” in Julia is equivalent to “1_000_000_000”.
using Dates
# If Dates is not installed, go to the pkg interface ("]") and
# type "add Dates" and try this code again
for i in 1:1_000_000_000
if i == 1
println("Starting!")
println(now())
println(" ")
end
if i == 500_000_000
println("Half way through. I counted to 500 million.")
println(now())
println(" ")
end
if i==1_000_000_000
println("Done. I counted to 1 billion.")
println(now())
end
end
# fin
If you copy and paste that into a *.jl file, you’ll see colored markup.
Double clicking the Julia link on the start menu opens up Julia in Windows Terminal by default (on my computer).
Here’s what Windows Terminal looks like with Julia running:
FYI, You can also open Julia from within Windows Terminal, just pop open the run prompt (win key + R) then type “wt” to open up Windows Terminal. It opens up Powershell by default, but there’s a little drop down that allows you to switch to Julia. Neat!
In a couple of seconds, Julia will load:
There are a few modes in the Julia interface to know about that you can read about here:
REPL mode (“julia>”) – This is the interface for Julia. Enter in all of your commands here. If you are in another mode, hit backspace to get back to REPL.
Help (“help?>”) – Enter a question mark (“?”), you enter the help context. You can query commands by typing the command name here.
Note: You need to load any package before accessing the help file btw, so if you type “?” then “Pkg”, you get an error. First, load Pkg with “using Pkg” then “?” then “Pkg”, and you’ll get the help file.
Note: You can also find help files for subcommands of packages. For example, after loading Pkg, you can type “Pkg.status()” to get a list of all installed packages. In the help screen (again, hit “?” to access it), type “Pkg.status” to see a help file for Pkg.status(). Similarly, if you want to learn about subpackages within Tidier, you need to list them after a dot, e.g., “Tidier.TidierDates”, or subsubpackages/commands by stringing multiple dots, e.g., “Tidier.TidierDates.difftime”.
Hit backspace to go back to REPL.
Shell (“shell>”)- Hit the semicolon (“;”) to get to the system shell. I have no idea how accessing the shell is of any value to me for what I’d use Julia for.
In Windows, you need to secondarily open Powershell by then typing “powershell” or the command prompt by typing “cmd”.
Hit backspace to go back to REPL.
Pkg to install/add new packages (“Pkg>”) – Aka installing new programs.
Type “add” and the name of the package of interest to install the package. E.g., “add Dates”.
Type “status” to see installed packages.
Type “update” to update all packages.
Hit backspace to go back to REPL.
But how do you run scripts from Notepad++ in Julia’s REPL mode? When you want to run bits of your script, simply copy and paste it into the Julia REPL interface. Note: One little glitch is that when you paste into REPL, the last line doesn’t load until you hit enter, you’ll see it just chilling on the input (e.g., “Julia > end”) when you copy/paste. You can do a workaround by having the last line of your code be a comment that isn’t actually needed to run your code. I’m using “# fin” as my last-line comment because it’s super classy. If you see “# fin” hanging out on the “Julia>” input line in REPL, just delete it before pasting anything else or your first line will follow “# fin” and be interpreted as a comment by Julia.
If you copy above and paste the “count to a billion” code from Notepad++ into the Windows Terminal running Julia, you get the following:
Cool! Julia counted to 1 billion in a little over 1 second. WOW THAT’S FAST!
In Part 2, I show an alternative way of running a script you are updating and saving in Notepad++ from within Julia, rather than copying and pasting everything.
Option 2 – Visual Studio Code with the Julia extension, aka the R Studio of Julia
R Studio is the most iconic Integrated Development Environment (IDE) for R. There were a few projects intending to be IDEs for Julia (e.g., Atom and Juno) that have halted development in support of Visual Studio (VS) Code’s Julia extension. VS Code is a general-purpose IDE developed by Microsoft that’s widely used in computer science and is available for all sorts of operating systems, not just Windows. VS Code should not be confused with Visual Studio, which is another IDE that Microsoft makes. The core of VS Code is open source, but the specific VS Code download from Microsoft isn’t.
Despite being a long-time Windows and Office user, I’m really not a fan of Microsoft products. They tend to be bloated and include whatever is trendy in the business world. VS Code is pretty bloat-free but does include a ‘bloaty’ AI assistant. I find VS code to be a bit overwhelming, which is why I like Notepad++.
You can also install VS Code as a portable app, so presumably you can have a portable version of Julia and also a portable version of VS Code both running from a thumbdrive or desktop folder without requiring an install. Details are here: https://code.visualstudio.com/docs/editor/portable
I might one day switch over to VS Code, but for now I’m sticking with Notepad++ and Windows Terminal.
Option 3 – Using Pluto notebooks, aka the Julia equivalent to Jupyter notebooks
Jupyter notebooks are ‘reactive’ notebooks that allow you to write and execute code in a browser, and see results in-line. Jupyter notebooks are great but require Python for their use. Pluto is very similar to Jupyter notebooks except implemented using Julia code alone — no requirement for Python. You can read all about Pluto here.
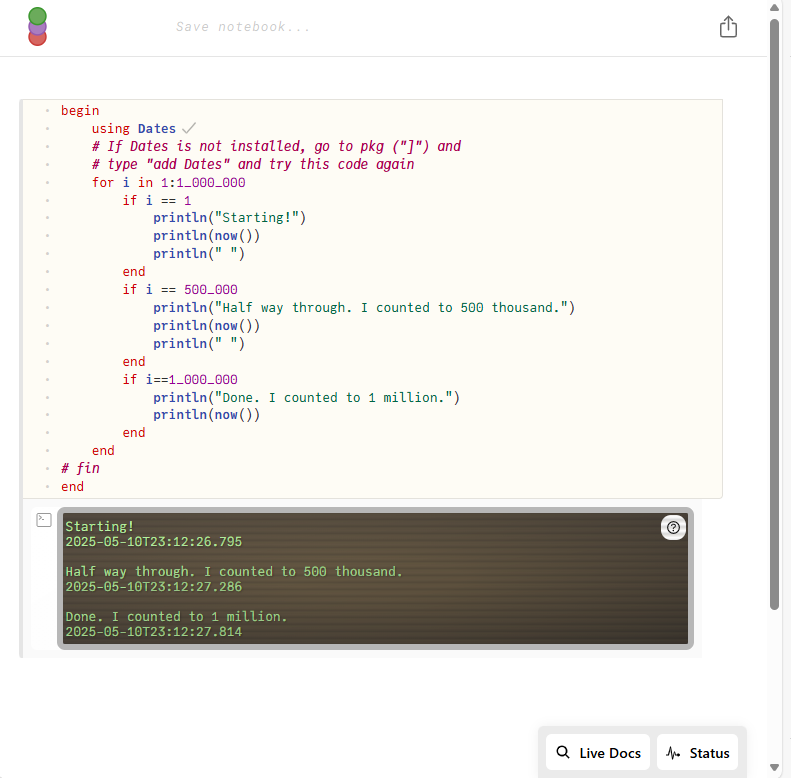
After installing it (‘using Pkg’ and ‘Pkg.add Pluto’), you can run Pluto in a browser by typing ‘Pluto.run()’. You can then run Julia interactively in your browser. If you want to run a block of code all at once (rather than line-by-line), you need to add a “begin” before all of the code and “end” after all of the code and indent what’s in between. Here’s an example of what this looks like, adapting some code for counting to 1 billion from above. (Note that this was taking A REALLY LONG TIME so I made it count to 1 million and not 1 billion.) You’ll see that the code has “begin” and “end” and everything is indented in between. The Julia output shows up below.
Pluto is REALLY COOL and seems user friendly for simple projects. I’m worried about how slow it was compared to the Julia in Windows Terminal. I’ll probably explore it a bit later. For now, I’m sticking with Notepad++ and Julia in Windows Terminal.
Installing packages in Julia
Stata is nice in that it comes with built-in functionality that allows you to do 95% of what you’re trying to do right out of the box. Occasionally you’ll need to install additional ado programs via SSC. Julia (like R) is limited in what it can do out of the box and requires you to install additional packages to add necessary functionality. Julia’s packages are a 2-step process:
Add (ie install) packages of interest.
In your script, call the package with “using”. (There’s also something called “import” that you can read about here that you may want to use instead of “using”. I’m still not entirely sure of the fundamental differences between “import” and “using”, so I’m sticking with “using” for now.)
The great thing about Julia is that its package management is VERY simple and baked into its interface. It ships with a package manager “Pkg” (details here) that you can load (“using Pkg”) and then call use to install other packages in a script, or alternatively you can switch over to the package management interface. In the REPL (aka “Julia”), simply hit a closing non-curly bracket (“]”) to open the package manager. Exit the package manager back to REPL by hitting backspace.
Above, you’d just hit the “]” key and see:
Again, just hit backspace to get out of the package manager back into Julia’s REPL interface.
Here’s an example for using Pkg in REPL or a script to download Tidier. Since Tidier is a metapackage with TONS of other packages inside of it, so it’ll take a bit of time to install (“add”), and also will take a bit of time to load (“using”) the first time. Subsequent times that you load (“using”) Tidier will be faster, but it’ll still take ~15 seconds to load each time.
using Pkg # need to make Pkg available to Julia
Pkg.add("Tidier")
#fin
Example for using the package manager, which you enter by hitting “]” in REPL:
add Tidier
Then hit backspace to exit the package manager back to REPL.
After these packages are installed, you can use them, but you need to make them available to Julia in your script, such as the following (Tidier will take a bit to load the first time, be patient — it’s faster with future loads):
using Tidier
[code that uses Tidier]
# fin
To update packages, use the Pkg.update() functionality, in REPL:
I recently had to make a figure that showed relationship between variables. I tried a few different software packages and ultimately decided that Graphviz is the easiest. Thanks to dreampuf for their Graphviz online program! I used this web-based implementation and didn’t have to install Graphviz on my computer. So for this, we’ll be using this online Graphviz package: https://dreampuf.github.io/GraphvizOnline
I wrote a basic Stata script that inputs data and then outputs Graphviz code that you can copy and paste right into the Graphviz website above. (I strongly strongly strongly recommend saving your Graphviz code locally on your computer as a text file. On Windows I use Notepad++. Don’t save this code in a word processor because it will do unpredictable things to the quotes.) You can then tweak the settings of the outputted Graphviz code to your liking. See all sorts of settings in the left-sided menu here: https://graphviz.org/docs/nodes/
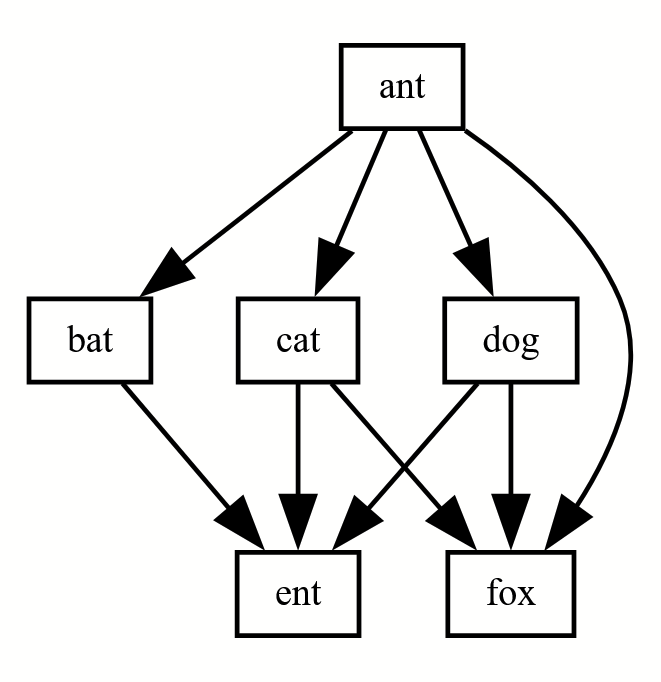
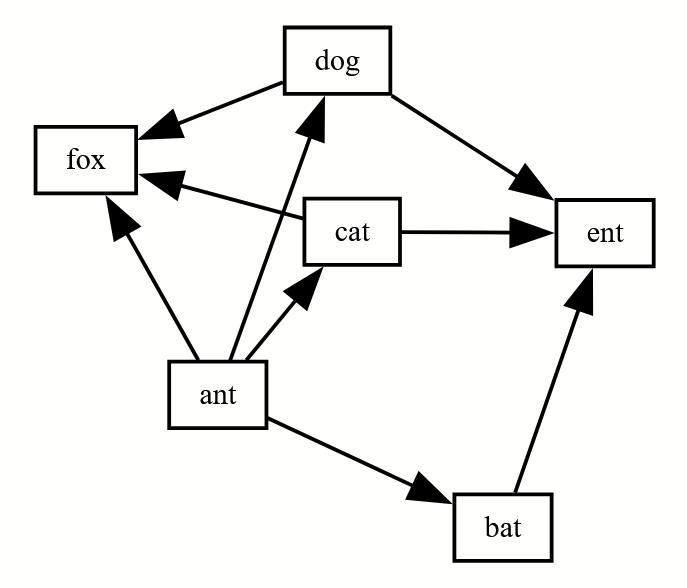
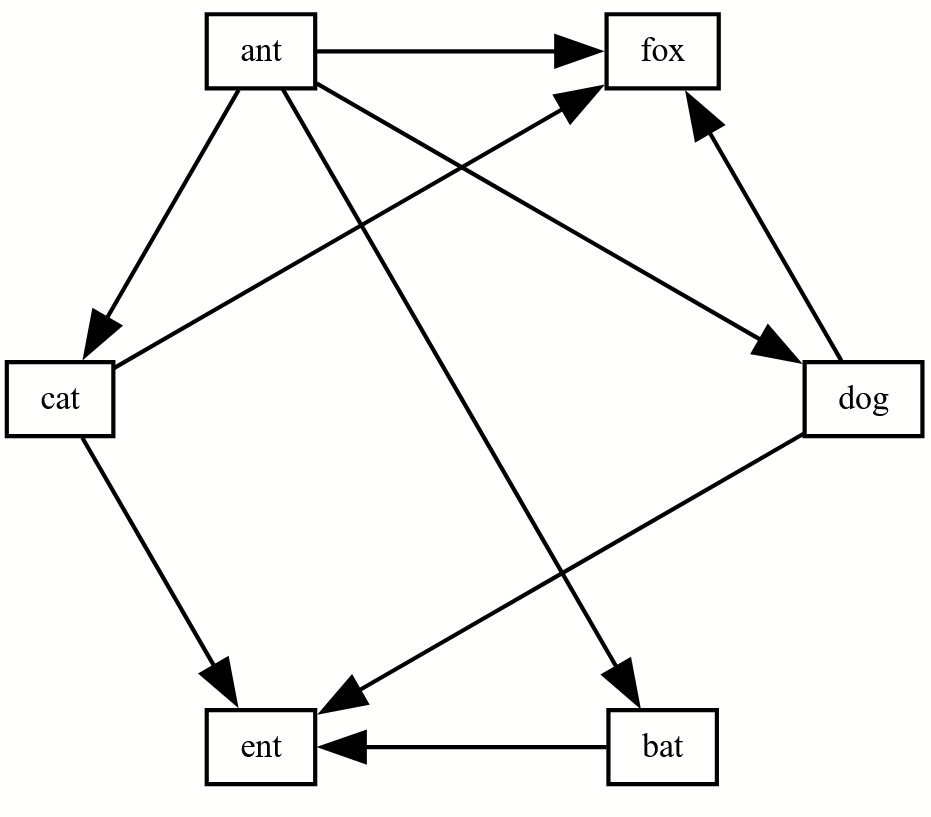
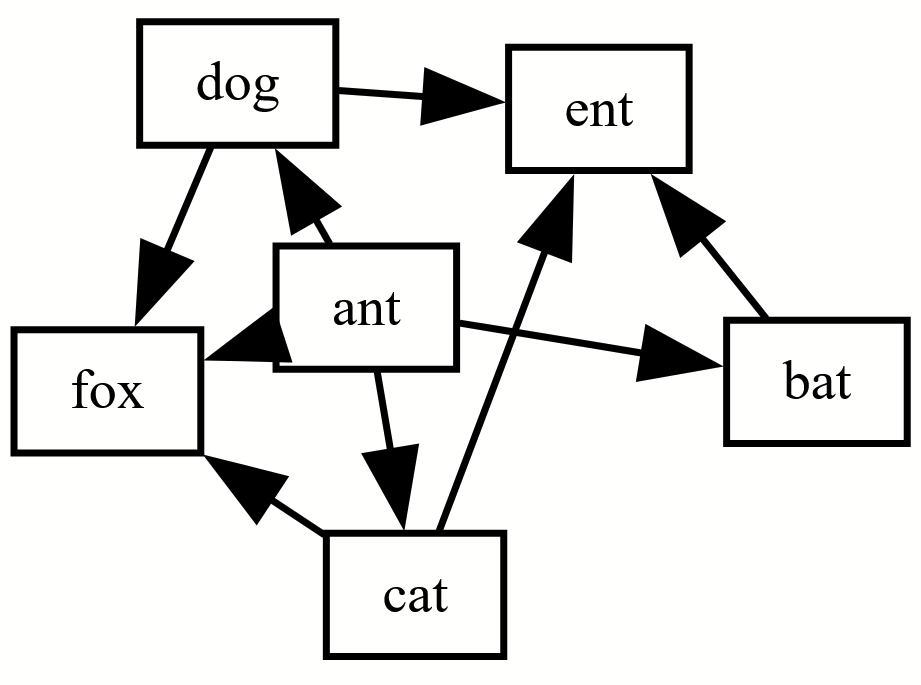
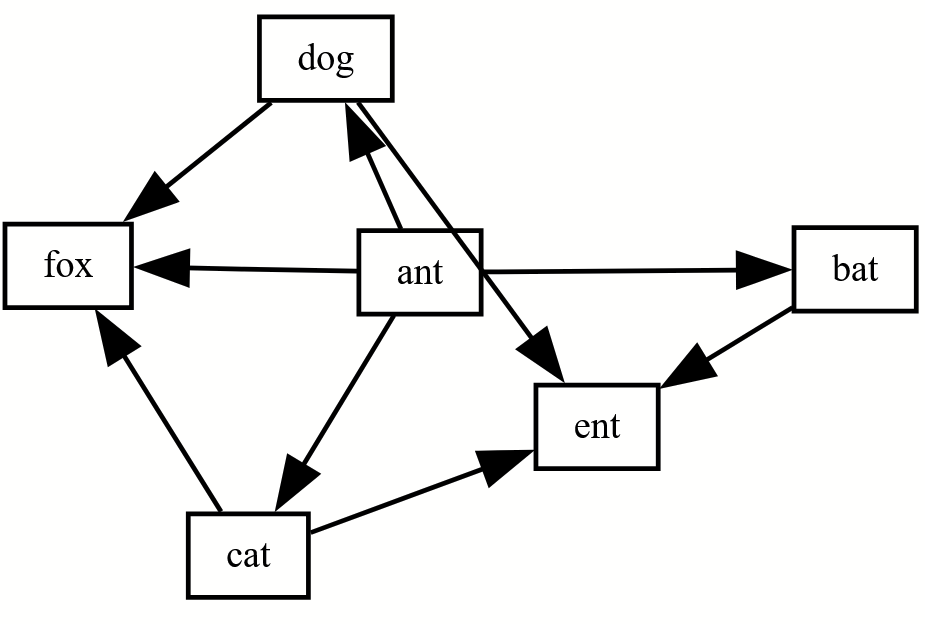
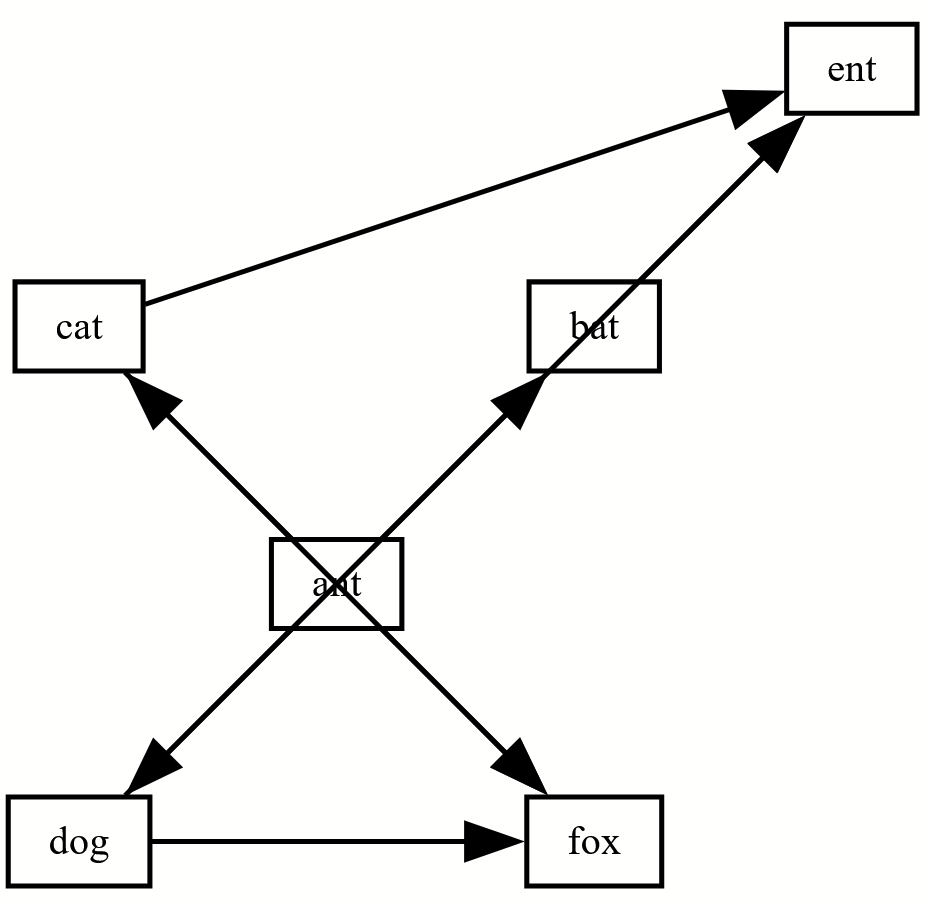
Originally I wanted this to be a network graph (“neato”) but ultimately liked how it looked best in the hierarchical graph (“dot”). You can change between graph types using the engine dropdown menu on the top right of the Graphviz online website. You can also change the file type to something that journals will use, like PNG, on the top right.
Code to output Graphviz code from your Stata database
Run the following in its entirety from a Stata do file.
clear all // clear memory
//
// Now input variables called 'start' and 'end#'.
// 'start' is the originating node and 'end#' is
// every node that 'start' connects to.
// If you need additional 'end#' variables, just add them
// using strL (capital L) then the next 'end#' number.
// In this example, there's 1 'start' and 4 'end#'
// so there are 5 total columns.
input strL start strL end1 strL end2 strL end3 strL end4
"ant" "bat" "cat" "dog" "fox"
"bat" "ent" "" "" ""
"cat" "ent" "fox" "" ""
"dog" "ent" "fox" "" ""
end // end input
//
// The following code reshapes the data from wide
// to long and drops all subsequent blank variables
// from that rotation (if any).
gen row = _n //make row variable
reshape long end, i(row) j(nodenum) // reshape
drop if end=="" // drop empty cells
keep start end // just need these variables
//
// The following loop renders the current Stata
// dataset as Graphviz code. Since this uses loops
// and local macros, it needs to be run all at once
// in a do file rather than line by line.
local max = _N
quietly {
// Start of graphviz code:
noisily di ""
noisily di ""
noisily di ""
noisily di ""
noisily di "// Copy everything that follows"
noisily di "// and paste it into here:"
noisily di "// https://dreampuf.github.io/GraphvizOnline"
noisily di "digraph g {"
//
// This prints out the connection between
// each 'start' node and all connected
// 'end#' nodes one by one.
forvalues n = 1/`max' {
noisily di start[`n'] " -> " end[`n'] ";"
}
//
// Global graph attributes follows.
// "bb" sets the size of the figure
// from lower left x, y, then upper right x, y.
// There are lots of other settings here:
// https://graphviz.org/docs/graph/
// ...if adding more, just add between the final
// comma and closing bracket. If adding several
// additional settings here, separate each with
// a comma.
// Note that this has an opening and closing tick
// so the quotes inside print like characters
// and not actual stata code quotes.
noisily di `"graph [bb="0,0,100,1000",];"'
//
// The next block generates code to render each
// node. First, we need to reshape long(er) so that
// all of the 'start' and 'end#' variables are all
// in a single column, delete duplicates, and
// sort them.
rename start thing1
rename end thing2
gen row = _n
reshape long thing, i(row) j(nodenum)
keep thing
duplicates drop
sort thing
//
// Now print out settings for each node. These
// can be fine tuned. Lots of options for
// node formatting here:
// https://graphviz.org/docs/nodes/
local max = _N
forvalues n= 1/`max' {
noisily di thing[`n'] `" [width="0.1", height="0.1", fontsize="8", shape=box];"'
}
// End of graphviz code:
noisily di "}"
noisily di "// don't copy below this line"
noisily di ""
noisily di ""
noisily di ""
noisily di ""
}
// that's it!
The above Stata code prints the following Graphviz code in the Stata output window. This code can be copied/pasted to the Graphviz website linked above. (Make sure to save a backup of this Graphviz code as a txt file on your computer!!) Make sure your Stata screen is full size before running the above Stata code or it might insert some line breaks that you have to manually delete since the output width is (usually) determined by the window size. Also, if your node settings get long, it’ll also insert line breaks that you’ll have to manually delete.
// Copy everything that follows
// and paste it into here:
// https://dreampuf.github.io/GraphvizOnline
digraph g {
ant -> bat;
ant -> cat;
ant -> dog;
ant -> fox;
bat -> ent;
cat -> ent;
cat -> fox;
dog -> ent;
dog -> fox;
graph [bb="0,0,100,1000",];
ant [width="0.1", height="0.1", fontsize="8", shape=box];
bat [width="0.1", height="0.1", fontsize="8", shape=box];
cat [width="0.1", height="0.1", fontsize="8", shape=box];
dog [width="0.1", height="0.1", fontsize="8", shape=box];
ent [width="0.1", height="0.1", fontsize="8", shape=box];
fox [width="0.1", height="0.1", fontsize="8", shape=box];
}
// don't copy below this line
Example figures from outputted code above using the different Graphviz engines
Clicking the dropdown in the top right “engine” toggles between the figures below. You can learn more about these here: https://graphviz.org/docs/layouts/
Not shown below are “nop” and “nop2” which don’t render correctly for unclear reasons. Some of these will need to be tweaked to be publication quality, some of them frankly don’t work with this dataset. For this made up code, I think dot and neato look great!
Dot (hierarchical or layered drawing of directed graphs, my favorite for this project):
Neato (a nice network graph, called “spring model” layout):
Circo, aka circular layout:
fdp (force-directed placement):
sfdp (scalable force-directed placement):
twopi (radial layout):
osage (clustered graphs):
Patchwork (clustered graph using squarified treemap):
I’m a Linux novice and installed Stata 18 on my new Ubuntu 24.10 dual boot laptop. But! Stata doesn’t show up as an installed program in my launcher. I found the installed files, including the executable for the GUI-based version of Stata 18 (“xstata-se”) in the /usr/local/stata18/ folder. I wanted to make a desktop shortcut to that folder but there doesn’t seem to be an option to make a shortcut from the Ubuntu file launcher. Instead, I followed the directions from the user ‘forester’ here and did it from the terminal.
Pop open your terminal by clicking ctrl+alt+T and plop in the text that follows, substituting your user name where indicated below
sudo ln -s /usr/local/stata18/ /home/[your user name]/Desktop
After you enter your password, a new link should appear on your desktop
FYI: If you are using a different version of Stata, the number will be different for the Stata folder (e.g., stata19).
Also, I had tried to create a desktop link to the xstata-se file itself, but clicking the link wouldn’t run Stata. Popping open the parent folder that the executable lives in is pretty close so I’ll stick with it.
There are all sorts of models out there for performing regressions. This page focuses on 3 that are used for binary outcomes:
Logistic regression
Modified Poisson regression
Cox proportional hazards models.
Getting set up
Before you get going, you want to explicitly define your outcome of interest (aka dependent variable), primary exposure (aka independent variable) and covariates that you are adjusting for in your model (aka other independent variables). You’ll also want to know your study design (eg case-control? cross-sectional? prospective? time to event?).
Are your independent variables continuous or factor/categorical?
In these regression models, you can specify that independent variables (primary exposure and covariates that are in your model) are continuous or factor/categorical. Continuous variables can be specified with a leading “c.”, and examples might include age, height, or length. (“c.age”.) In contrast, factor/categorical variables might be New England states (e.g., 1=Connecticut, 2=Maine, 3=Mass, 4=New Hampshire, 5=RI, and 6=Vermont). So, you’d want to specifiy a variable for “newengland” as i.newengland in your regression. Stata defaults to treating the smallest number (here, 1=Connecticut) as the reference group. You can change that by using the “ib#.” prefix instead, where the # is the reference group, or here ib2.newengland to have Maine as the reference group.
Read about factor variables in –help fvvarlist–.
What about binary/dichotomous variables (things that are ==0 or 1)? Well, it doesn’t change your analysis if you specify a binary/dichotomous as either continuous (“c.”) or factor/categorical (“i.”). The math is the same on the back end.
Checking for interactions
In general, when checking for an interaction, you will need to specify if the two variables of interest are categorical or factor/categorical and drop two pound signs in between the two. See details on –help fvvarlist–. Here’s an example of how this would look, looking for an interaction between sex on age groups.
regress bp i.sex##c.agegrp
Source | SS df MS Number of obs = 240
-------------+---------------------------------- F(3, 236) = 23.86
Model | 9519.9625 3 3173.32083 Prob > F = 0.0000
Residual | 31392.8333 236 133.02048 R-squared = 0.2327
-------------+---------------------------------- Adj R-squared = 0.2229
Total | 40912.7958 239 171.183246 Root MSE = 11.533
------------------------------------------------------------------------------
bp | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
sex |
Female | -4.275 3.939423 -1.09 0.279 -12.03593 3.485927
agegrp | 7.0625 1.289479 5.48 0.000 4.52214 9.60286
|
sex#c.agegrp |
Female | -1.35 1.823599 -0.74 0.460 -4.942611 2.242611
|
_cons | 143.2667 2.785593 51.43 0.000 137.7789 148.7545
------------------------------------------------------------------------------
You’ll see the sex#c.agegrp P-value is 0.460, so that wouldn’t qualify as a statistically significant interaction.
Regressions using survey data?
If you are using survey analyses (eg need to account for pweighting), generally you have to use the svy: prefixes for your analyses. This includes svy: logistic, poisson, etc. Type –help svy_estimation– to see what the options are.
Logistic regression
Logistic regressions provide odds ratios of binary outcomes. Odds ratios don’t approximate the risk ratio if the outcome is common (eg >10% occurrence) so I tend to avoid them as I study hypertension, which occurs commonly in a population.
There are oodles of details on logistic regression in the excellent UCLA website. In brief, you want want to use a regression command, you can use “logit” and get the raw betas or “logistic” and get the odds ratios. Most people will want to use “logistic” to get the odds ratios.
Here’s an example of logistic regression in Stata. In this dataset, “race” is Black/White/other, so you’ll need to specify this as a factor/categorical variable with the “i.” prefix, however “smoke” is binary so you can either specify it as a continuous or as a factor/categorical variable. If you don’t specify anything, then it is treated as continuous, which is fine.
So, here you see that the odds ratio (OR) for the outcome of “low” is 2.96 (95% CI 1.13, 7.72) for Black relative to White participants and the OR for the outcome of “low” is 3.03 (95% CI 1.38, 6.64) for Other race relative to White participants. Since it’s the reference group, you’ll notice that White race isn’t shown. But what if we want Black race as the reference? You’d use “ib2.race” instead of “i.race”. Example:
Modified Poisson regression (sometimes called Poisson Regression with Robust Variance Estimation or Poisson Regression with Sandwich Variance Estimation) is pretty straightforward. Note: this is different from ‘conventional’ Poisson regression, which is used for counts and not dichotomous outcomes. You use the “poisson” command with subcommands “, vce(robust) irr” to use the modified Poisson regression type. Note: with svy data, robust VCE is the default so you just need to use the subcommand “, irr”.
As with the logistic regression section above, race is a 3-level nominal variable so we’ll use the “i.” or “ib#.” prefix to specify that it’s not to be treated as a continuous variable.
webuse lbw, clear
codebook race // see race is 1=White, 2=Black, 3=other
codebook smoke // smoke is 0/1
// set Black race as the reference group
poisson low ib2.race smoke, vce(robust) irr
// output:
Iteration 0: Log pseudolikelihood = -122.83059
Iteration 1: Log pseudolikelihood = -122.83058
Poisson regression Number of obs = 189
Wald chi2(3) = 19.47
Prob > chi2 = 0.0002
Log pseudolikelihood = -122.83058 Pseudo R2 = 0.0380
------------------------------------------------------------------------------
| Robust
low | IRR std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
race |
White | .507831 .141131 -2.44 0.015 .2945523 .8755401
Other | 1.038362 .2907804 0.13 0.893 .5997635 1.7977
|
smoke | 2.020686 .4300124 3.31 0.001 1.331554 3.066471
_cons | .3038099 .0800721 -4.52 0.000 .1812422 .5092656
------------------------------------------------------------------------------
Note: _cons estimates baseline incidence rate.
Here you see that the relative risk (RR) of “low” for White relative to Black participants is 0.51 (95% CI 0.29, 0.88), and the RR for other race relative to Black participants is 1.04 (95% CI 0.60, 1.80). As above, the “Black” group isn’t shown since it’s the reference group.
Cox proportional hazards model
Cox PH models are used for time to event data. This is a 2-part. First is to –stset– the data, thereby telling Stata that it’s time to event data. In the –stset– command, you specify the outcome/failure variable. Second is to use the –stcox– command to specify the primary exposure/covariates of interest (aka independent variables). There are lots of different steps to setting up the stset command, so make sure to check the –help stset– page. Ditto –help stcox–.
Here, you specify the days of follow-up as “days_hfhosp” and failure as “hfhosp”. Since follow-up is in days, you set the scale to 365.25 to have it instead considered as years.
stset days_hfhosp, f(hfhosp) scale(365.25)
Then you’ll want to use the stcox command to estimate the risk of hospitalization by beta blocker use by age, sex, and race with race relative to the group that is equal to 1.
stcox betablocker age sex ib1.race
You’ll want to make a Kaplan Meier figure at the same time, read about how to do that on this other post.
This specific example works with figures and text made within PowerPoint, YMMV if you are trying to embed pictures (eg microscopy). For that, you might want to use Photoshop or GIMP or the excellent web-based equivalent, Photopea. Just remember to output a file that is 1772×1772 pixels and saved as a jpeg.
Step 1: Make a square PowerPoint slide.
Open PowerPoint, make a blank presentation
Design –> slide size –> custom slide size
Change width to 15 cm and height to 15 cm (it defaults to inches in the US version of PPT)
Make your graphical abstract.
Save the pptx file.
Note: Following this bullet point is the one I made if you want to use the general format. Obviously it’ll need to be heavily modified for your article. I selected the colors using https://colorbrewer2.org. I’m not sure I love the color palette in the end, but it worked:
Step 2: Output your PowerPoint slide as an SVG file. I use this format since it’s a vector format that uses curves and lines to make an image that can be enlarged without any loss in quality. It doesn’t use pixels.
While looking at your slide in PowerPoint, hit File –> export –> change file type –> save as another file type.
In the pop up, change the “save as type” drop down to “scalable vector graphics format (*.svg)” and click save.
Note: For some reason OneDrive in Windows wouldn’t let me save an SVG file to it at this step. I had to save to my desktop instead, which was fine.
If you get a pop up, select “this slide only”.
Step 3: Set resolution in Inkscape
Open Inkscape, and open your new SVG file.
Note: In the file browser, it might look like a Chrome or Edge html file since Windows doesn’t natively handle SVG files.
When you have the SVG file open in Inkscape, click file –> export. You will see the export panel open up on the right hand side. Change the file type to jpeg. Above, change the DPI to 300 and the width and height should automatically change to 1772 pixels.
Here’s my approach as someone who practices at UVMMC, within the UVMHN.
CareEverywhere to find records in outside/non-UVMHN Epic and *also* outside non-Epic EMRs
Epic’s CareEverywhere works well with other hospital’s Epic implementations. Regionally, that means Dartmouth and the MGH/BWH/Partner’s network in Boston. (Lahey/BIDMC is switching to Epic soon as well.) In the 2020s, it has started working with non-Epic shops as well, including Community Health Center of Burlington. Many of these non-Epic shops are vendors for 15,000+ clinics and medical centers (eg, athenahealth, surescript, nextgen, particlehealth), so linking with these vendors will ping a broad array of clinics across the country. You need to link outside clinics and hospitals within CareEverywhere as a one-time step for each patient. I never assume that this linkage step was done because it usually isn’t.
To do a linkage, in CareEverywhere, click the little “e” next to the patient’s name in the left hand column or under the tabs (eg chart review, results) –> ‘Request Outside Records’. This might be hidden under ‘Rarely Used’. Once there, click the link that says ‘Find Outside Charts’. High-yield linkages to try are below. Bonus: click the star next to the names of these so they’ll show up as a favorite and you don’t have to search for them in other records!
Community Health Center of Burlington, inc – by searching “Community Health Center of Burlington”
Note: CHCB is sometimes listed as using NextGen or ParticleHealth, which you’ll see below. I usually ping them directly because one of those two vendors doesn’t work and I can’t remember which one it is.
Practices using athenahealth EHR – by searching “athenahealth” (not aetna, it’s like the Greek goddess Athena)
Note: This is what the private cardiology group in Timber Lane uses
Surescripts record locator gateway – by searching “surescripts”
Note: This is what the private OB group in Tilley uses
NextGen Share – by searching “nextgen”
ParticleHealth – By searching “particlehealth”.
Vermont Information Technology Leaders – aka VITL, which as of 2/2024 is broken (see the separate VITL section below) by searching “Vermont Information Technology Leaders”
Dartmouth Health – by searching “dartmouth”
Mass General Brigham – aka Partners by searching “mass general”
PRIMARY CARE HEALTH PARTNERS – a consortia of pediatric and adult primary care practices headquartered in Williston, search “primary care health partners”
Veterans Affairs/Department of Defense Joint HIE – aka the VA. Search “Veterans Affairs”.
A few regional hospitals to consider, based upon where they live:
Northwest Medical Center
Northeastern Vermont Regional Hospital
Rutland Regional Medical Center
For outside Epics: Finding information on CareEverywhere is pretty straightforward for other sites using Epic. In fact as of 2024, I’ve noticed that outside notes show up in-line with our notes in Chart Review! Super cool.
For non-Epic EMRs: There is usually one really ugly note from each group called “Summarization of episode note” or something like that in CareEverywhere –> Documents. These summarization notes are basically a snapshot of the entire medical record of these non-Epic linkages! Take a look: You’ll find labs, vitals, problem lists, notes, radiology reports, etc. They are unwieldy and usually ugly, but have lots of good info included. Keep scrolling all the way to the bottom.
Again, as of 2/2024, VITL’s CareEverywhere linkage is broken so those summarization notes for VITL don’t populate with anything useful.
VITL, aka VT’s HIE – An outstanding resource
The Vermont Information Technology Leaders (VITL) service is our regional health information exchange (HIE) for the state of VT and provides near real-time summary of notes, labs, radiology, etc from the state of Vermont. I can’t overstate how incredible this service is, especially getting outside hospital records and structured data from patients transferred from non-UVMHN hospitals in VT (eg NWMC, RRMC, NEVRH). Here’s the login: https://vitlaccess.vitl.net/login
Unfortunately, as of 2/2024, you need a separate login to get into VITL — it’s not a ‘single click’ from within Epic like HIXNY (see below). To get an account, please email vhiesupport@vitl.net with (1) name, (2) email address, and (3) location/department that the person works. I guess in theory you can do this for entire departments all at once. The VITL folks then apparently reach out to a Trained Security Officer within UVMHN (Jennifer Parks, the chief compliance officer) who verifies things and then VITL folks will grant access. I’m guessing you then get an email to set up an account afterwards. (Perhaps cc Jennifer Parks in the initial email to the vhiesupport email to expedite things? Who knows. Seems like it would save a step.)
Anyway, nearly everything of value within VITL exists within the All Results tab in their web portal. This includes notes, labs, radiology reports, etc. If you poke around in other tabs, you’ll find problem lists, medication lists, billing codes, etc. But the best bang-for-the-buck is in the All Results tab.
HIXNY, aka NY’s HIE
HIXNY is New York’s HIE (well, it looks like it’s the eastern part of NY north of NYC per the map here). You can find it under epic –> chart review –> encounters –> HIXNY (one of the buttons at the top next to Epiphany). This will pop up HIXNY is a separate window. Whether a patient is included is a bit hit-or-miss as I guess it’s an opt in for patients? I’ve had pretty good luck with patients having active accounts if they are middle aged or a senior. I bet that primary care practices across the lake must have some mechanism to get patients signed up HIXNY as part of their care. It looks like there is some sort of consent form that institutions can have patients complete. I’m not sure that UVMHN is actively having patients complete this form.
Legacy Chart, aka pre-Epic, “old records” from hospitals in UVMHN
When UVMHN brought other hospitals into the network, it saved much of the scanned/dictated prior records in this funny app linked within in Epic called ‘Legacy Chart’. This is very helpful for finding old records from Porter, CVMC, CVPH, Etown, Ti, etc. You will find it next to the HIXNY and Epiphany buttons under epic –> chart review –> encounters –> Legacy Chart. When you click on it, it will pull open this weird file structure (if there are old records to be found). I’ve found critical information from old echocardiograms, colonoscopies/endoscopies, PFTs, op notes, consult notes, H&Ps, etc that has changed management.
Pre-Epic notes using a Notes Filter
This isn’t a setting or linkage as much as it is setting filters strategically within Epic’s Chart Review –> Notes tab to pull up things from the pre-Epic time (Epic turned on 10/2010). Before Epic there was our super old EMR called HISSPROD and later a pseudo EMR called Maple. Lots of HISSPROD discharge summaries and notes from Maple were brought into Epic.
When you are in a patient’s chart who had lots of care pre-2010, you can build this filter. (You unfortunately can’t build this filter unless old notes of the below type exist since they won’t appear as filter options.) Go to epic –> chart review –> notes –> filters –> type then select as many of these as appear:
Amb Consult
Amb Eval
Amb General Summary
Amb Letter
Amb Procedure
Amb Progress Note
Brief Procedure Op Note
Clinical Progress Notes
Communications
Emergency Room Record
H&P – (this unfortunately also will give recent H&Ps, but also gives old H&Ps, back then called ‘History and Physical’)
HISSPROD Discharge Summary
Op Procedure Note
Update Letter
You might need to try to build this shortcut in a few separate patients with pre-Epic documents. The list above will (mostly) pull in records from pre-Epic times.
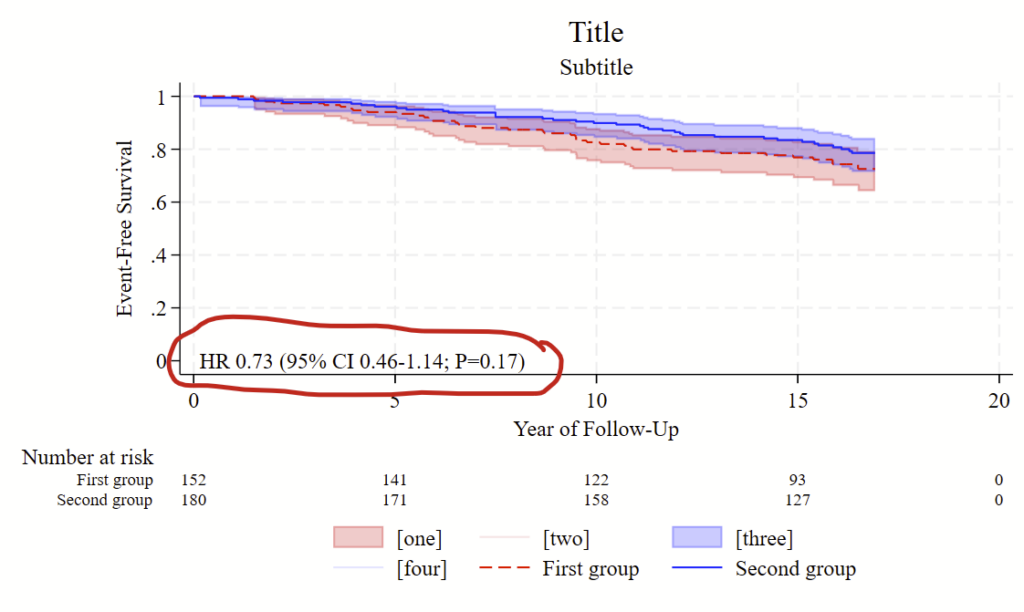
I recently made a figure that estimates a hazard ratio and renders it right on top of a Kaplan Meier curve in Stata. Here’s some example code to make this.
Good luck!
// Load example dataset. I got this from the --help stset-- file
webuse diet, clear
// First, stset the data.
stset dox /// dox is the event or censor date
, ///
failure(fail) /// "fail" is the failure vs censor variable
scale(365.25)
// Next, estimate a cox ph model by "hienergy"
stcox hienergy
// now grab the bits from output of this
local hrb=r(table)[1,1]
local hrlo=r(table)[5,1]
local hrhi=r(table)[6,1]
local pval = r(table)[4,1]
// now format the p-value so it's pretty
if `pval'>=0.056 {
local pvalue "P=`: display %3.2f `pval''"
}
if `pval'>=0.044 & `pval'<0.056 {
local pvalue "P=`: display %5.4f `pval''"
}
if `pval' <0.044 {
local pvalue "P=`: display %4.3f `pval''"
}
if `pval' <0.001 {
local pvalue "P<0.001"
}
if `pval' <0.0001 {
local pvalue "P<0.0001"
}
di "original P is " `pval' ", formatted is " "`pvalue'"
di "HR " %4.2f `hrb' " (95% CI " %4.2f `hrlo' "-" %4.2f `hrhi' "; `pvalue')"
// Now make a km plot. this example uses CIs
sts graph ///
, ///
survival ///
by(hienergy) ///
plot1opts(lpattern(dash) lcolor(red)) /// options for line 1
plot2opts(lpattern(solid) lcolor(blue)) /// options for line 2
ci /// add CIs
ci1opts(color(red%20)) /// options for CI 1
ci2opts(color(blue%20)) /// options for CI 2
/// Following this is the legend, placed in the 6 O'clock position.
/// Only graphics 5 and 6 are needed, but all 6 are shown so you
/// see that other bits that can show up in the legend. Delete
/// everything except for 5 and 6 to hide the rest of the legend components
legend(order(1 "[one]" 2 "[two]" 3 "[three]" 4 "[four]" 5 "First group" 6 "Second group") position(6)) ///
/// Risk table to print at the bottom:
risktable(0(5)20 , size(small) order(1 "First group" 2 "Second group")) ///
title("Title") ///
t1title("Subtitle") ///
xtitle("Year of Follow-Up") ///
ytitle("Event-Free Survival") ///
/// Here's how you render the HR. Change the first 2 numbers to move it:
text(0 0 "`: display "HR " %4.2f `hrb' " (95% CI " %4.2f `hrlo' "-" %4.2f `hrhi' "; `pvalue')"'", placement(e) size(medsmall)) ///
yla(0(0.2)1)




{kind=link}
{kind=link}