As we learned in part 5, Table 1 describes your analytical population at baseline by your exposure. For those using a continuous variable as an exposure, it’s by quantile (e.g., tertile, quartile) of the exposure. I propose a table known as “Table 2” that describes the outcome of interest by the exposure used in Table 1. You might have seen something along the lines of this in papers before, and we are going to call it “Table 2”. It’s not a universal table in observational epidemiology, so calling it “Table 2” is a bit much. But we’ll call it “Table 2” for our purposes.
Columns
The columns should be identical to that in your Table 1. (I suggest having an “All” column if you don’t have one in your Table 1 though.)
Rows
In Table 1, I suggested having an N and range for continuous variables of your quantiles. I suggest not including those in your Table 2 if they are already in your Table 1, since it’s duplicative. I suppose it might be helpful for error checking to have them in table 2, and confirming that they are identical to your Table 1. But, I suggest not including a row for Ns and ranges in your Table 2 that is included in the manuscript.
In a very simple Table 2, there might be a single row: the outcome in the analytical population. It might look like this:
All
Tertile 1
Tertile 2
Tertile 3
All
BUT! There might be a stratification of interest in your table. in the REGARDS study, we often stratify by Black vs. White race or by sex. So, you might also include rows for each subsequent group, like this:
All
Tertile 1
Tertile 2
Tertile 3
All
Black participants
White participants
Finally, for subgroups, you might opt to include a minimally-adjusted regression comparing your strata. in this example, we could use a modified Poisson regression (i.e., Poisson regression with sandwich or robust variance estimators, Zou’s method) to compare risk of the outcome overall an in each tertile. I’d just adjust for age and sex in this example. So:
All
Tertile 1
Tertile 2
Tertile 3
All
Black participants
White participants
RR, Black vs. White (ref)
Cell
Here, I suggest presenting # with event/# at risk (percentage with event) in each cell, except in the RR row, which would present RR and the 95% confidence interval. Example (totally made up numbers here and some placeholder ##’s, as FYI):
All
Tertile 1
Tertile 2
Tertile 3
All
1200/3000 (40%)
300/1000 (30%)
400/1000 (40%)
500/1000 (50%)
Black participants
500/1000 (50%)
##/## (##%)
##/## (##%)
##/## (##%)
White participants
700/2000 (35%)
##/## (##%)
##/## (##%)
##/## (##%)
RR, Black vs. White (ref)
1.42 (1.30-1.55)
1.20 (1.15-1.25)
1.22 (1.18-1.30)
1.21 (1.19-1.28)
That’s it! Even if you don’t include this table, it’s super handy to have to describe the outcome in the text.
Time to event analyses
For time to event analyses, this should be modified a bit. Instead, this should focus on events, follow-up (in person-years), and incident rate (e.g., events in 1000 person-years).
Visualization of your continuous exposure in an observational epidemiology research project
As we saw in Part 5, it’s important to describe the characteristics of your baseline population by your exposure. This helps readers get a better understanding of internal validity. For folks completing analyses with binary exposures, part 6 isn’t for you. If your analysis includes continuous exposures or ordinal exposures with at least a handful of options, read on.
I think it’s vitally important to visualize your exposure before moving any further forward with your analyses. There are a few reasons that I do this:
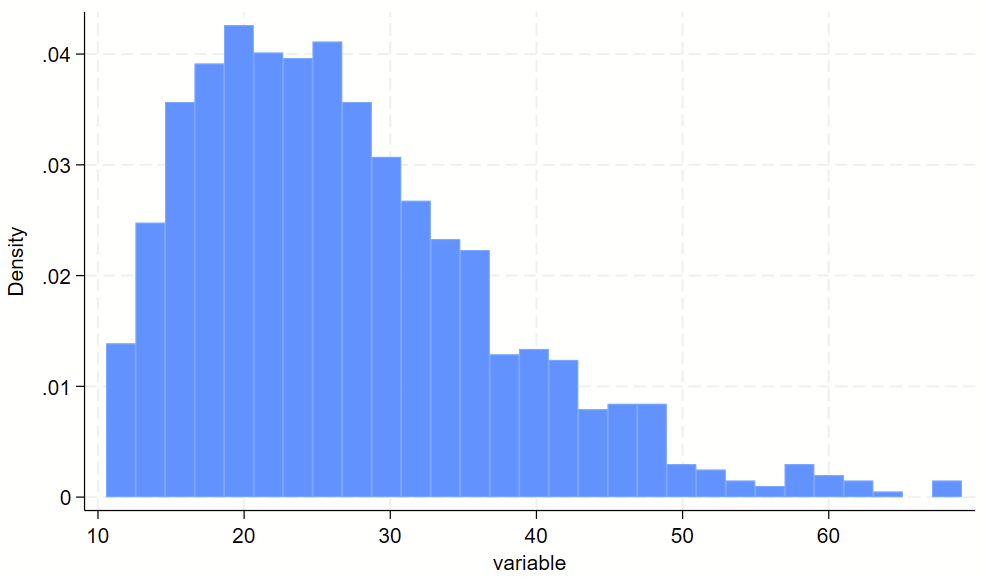
Understand the distribution of your exposure. Looking at the raw spread of your data will help you understand if it has a relatively normal distribution, if it’s skewed, if it is multimodal (eg, has several peaks), or if it’s just plain old weird looking. If your exposure is non-normally distributed, then you’ll need to consider the implications of the spread in your analysis. This may mean log-transforming, square root-transforming (if you have lots of zeros in your exposure’s values), or some other sort of transformation.
Note: make sure to visualize your transformed exposure value!
Look for patterns that need exploring. You might notice a huge peak at a value of “999”. This might represent missing values, which will need to be recoded. You might notice that values towards the end of the tails of the bell curve might spike up at a particular value. This might represent values that were really above or below the lower limit of detection. You’ll need to think about how to handle such values, possibly recoding them following the NHANES approach as the limit of detection divided by the square root of 2.
Understand the distribution of your exposure by key subgroups. In REGARDS, our analyses commonly focus on racial differences in CVD events. Because of this, I commonly visualize exposures with overlaid histograms for Black and White participants, and see how these exposure variables differ by race. This could easily be done for other sociodemgraphics (notably, by sex), anthropometrics, and disease states.
Ways to depict your continuous exposure
Stem and leaf plots
Histograms
Kernel density plots
Boxplots
1. Stem and leaf plots
Stem and leaf plots are handy for quickly visualizing distributions since the output happens essentially instantaneously, whereas other figures (e.g., histograms) take a second or two to render. Stem and leaf plots are basically sideways histograms using numbers. The Stata command is –stem–.
* load the sysuse auto dataset and clear all data in memory
sysuse auto, clear
* now render a stem and leaf plot of weight
stem weight
Here’s what you get in Stata’s output window. You’ll see a 2 digit number (eg “17**”) followed by a vertical bar then another 2 digit number (eg “60”). That means that 1 person has a value of 1760. If there are multiple numbers after the bar, then that means that there are more than 1 number in that group. For example, the “22**” stem has “00”, “00”, “30”, “40”, and “80” leaves, meaning that there is 2200, 2200, 2230, and 2280 as values in this dataset.
For stems with a huge amount of values, you’ll see some other characters appear to split up the stem into multiple stems. For example, here’s the output for stem of MPG:
You’ll notice that the 10-place stem is split into 4 different stems, “1t”, “1f”, “1s”, and “1.”. I’m guessing that *=0-1, t=2-3, f=4-5, s=6-7, .=8.9.
2. Histograms
A conventional histogram splits continuous data into several evenly-spaced discrete groups called “bins”, and visualizes these discrete groups as a bar graph. These are commonly used but in Stata can’t be used with pweighting. See kernel density plots below for consideration of how to use pweighting.
Let’s see how to do this in Stata, with some randomly generated data that approximates a normal distribution. While we’re at it, we’ll make a variable called “group” that’s 0 or 1 that we’ll use later. (Also note that this dataset doesn’t use discrete values, so I’m not specifying the discrete option in my “hist” code. If you see spaces in your histogram because you are using discrete values, add “, discrete” after your variable name in the histogram line.)
clear all
// set observations to be 1000:
set obs 1000
// set a random number seed for reproducibility:
set seed 12345
// make a normally-distributed variable, with mean of 5 and SD of 10:
gen myvariable = rnormal(5,10)
// make a 0 or 1 variable for a group, following instructions for "generate ui":
// https://blog.stata.com/2012/07/18/using-statas-random-number-generators-part-1/
gen group = floor((1-0+1)*runiform() + 0)
// now make a histogram
hist myvariable
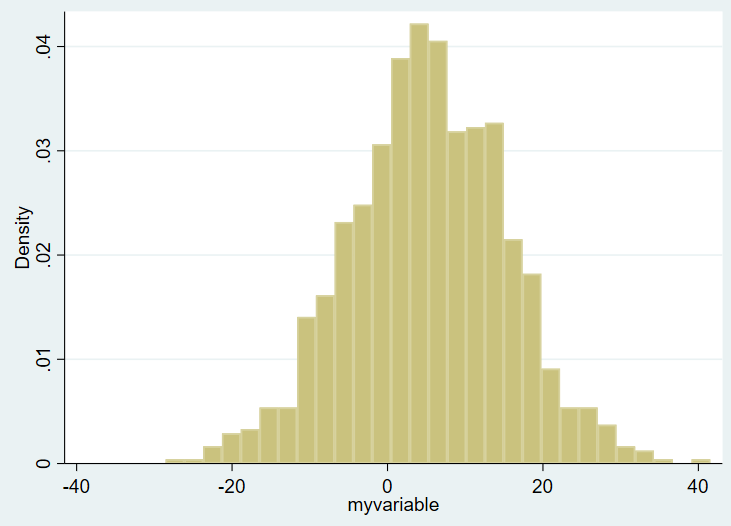
Here’s the overall histogram:
On the X axis you see the ranges of the values of variable of interest, from around -30 to about +40. On the Y axis you see the density plot. I want to show this same figure by group, however, and the bins are not currently transparent. You won’t be able to tell one group from another. So, in Stata, you need to use the “twoway histogram” option instead of just “histogram” and specify transparent colors of the figure using the %NUMBER notation. We’ll also add a legend. We’ll set the scheme to s1mono to get rid of the ugly default blue surrounding box as well. Example:
// set the scheme to s1mono:
set scheme s1mono
// now make your histogram:
twoway ///
(hist myvariable if group==0, color(blue%30)) ///
(hist myvariable if group==1, color(red%30)) ///
, ///
legend(order(1 "Group==0" 2 "Group==1"))
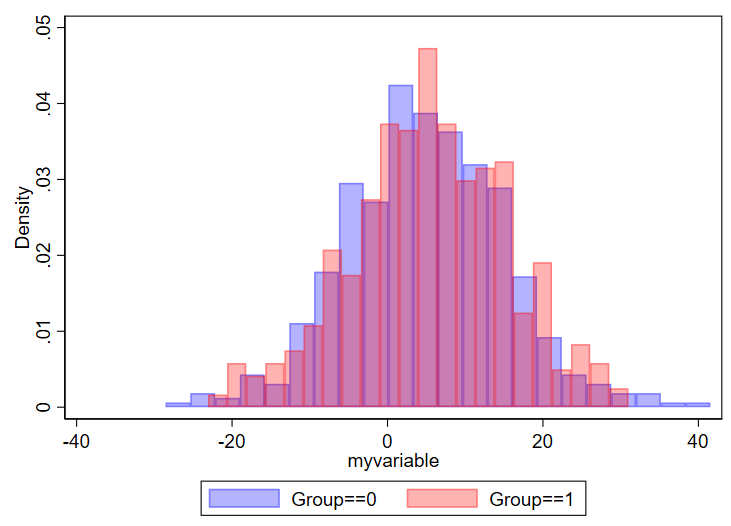
Here’s what you get:
You can modify things as needed. Something you might consider is changing the density to count or frequency, which is done by adding “frequency” or “percent” after the commas but before the colors. You might also opt to select different colors, which you can read about selection of colors in this editorial I wrote with Mary Cushman.
Considerations for designing histograms
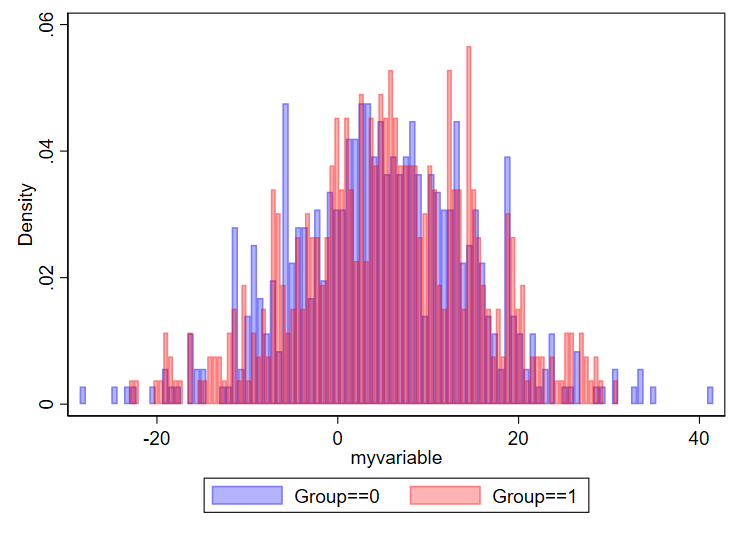
One question is how many bins you want. I found this nice 2019 article by Regina L. Nuzzo, PhD (PDF link, PubMed listing) that goes over lots of considerations for the design of histograms. I specifically like the Box, which lists equations to determine number of bins and bid width. In general, if you have too many bins, your data will look choppy:
// using 100 bins here
twoway ///
(hist myvariable if group==0, color(blue%30) bin(100)) ///
(hist myvariable if group==1, color(red%30) bin(100)) ///
, ///
legend(order(1 "Group==0" 2 "Group==1"))
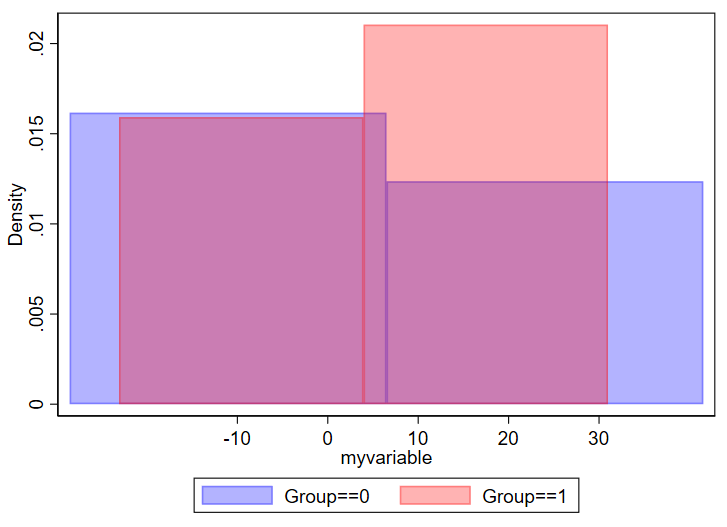
And if you have too few, you won’t be able to make sense of the overall structure of the data.
// using 2 bins here
twoway ///
(hist myvariable if group==0, color(blue%30) bin(2)) ///
(hist myvariable if group==1, color(red%30) bin(2)) ///
, ///
legend(order(1 "Group==0" 2 "Group==1"))
Be thoughtful about how thinly you want to splice your data.
What about histograms on a log scale?
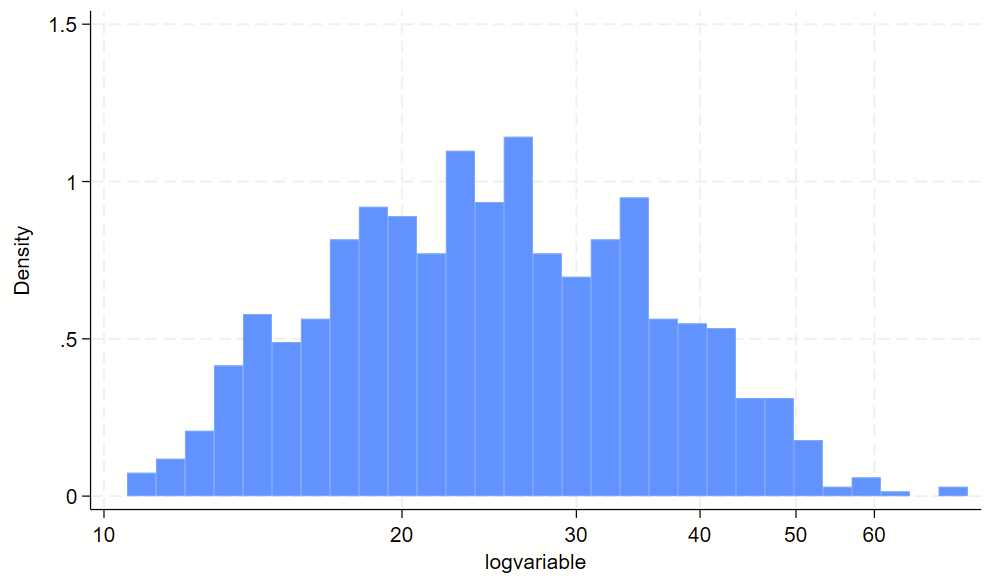
You might have some sort of skewed variable that you want to show on a log scale. The easiest way to do this is to (1) make a log-transformed variable of this, and (2) make a histogram of the log-transformed variable. For part #2, you’ll want to print the labels of the original variable in their log-transformed spot, otherwise you’ll wind up with labels for the log-transformed variable, which are usually not easy to interpret. See the `=log(number)’ trick below for how to drop non-log transformed labels in log-transformed spots.
// clear dataset and make skewed variable
clear all
set obs 1000
gen variable = 10+ ((rbeta(2, 10))*100)
// visualize non-log transformed data
twoway ///
(hist variable) ///
, ///
xlab(10 "10" 20 "20" 30 "30" 40 "40" 50 "50" 60 "60")
// make a long-transformed variable
gen logvariable=log(variable)
// visualize non-log transformed data
// plop the labels in the spots where the "original" labels should be
twoway ///
(hist logvariable) ///
, ///
xlab(`=log(10)' "10" `=log(20)' "20" `=log(30)' "30" `=log(40)' "40" `=log(50)' "50" `=log(60)' "60")
Here’s the raw variable.
Here is the histogram of the log transformed variable. Notice that the 10-60 labels are printed in the correct spots with the `=log(NUMBER)’ code above.
3. Kernel density plots
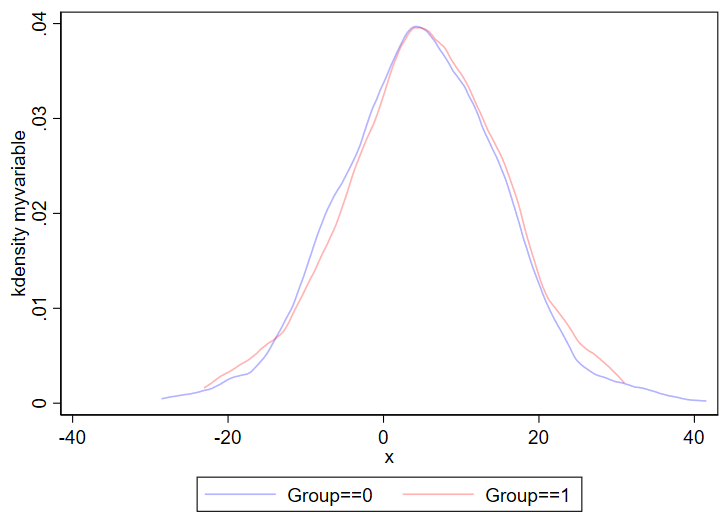
Kernel density plots are similar to histograms, except it shows a smoothed line over your data’s distribution. Histograms are less likely to hide outliers since kernel density plots can smooth over outliers. The code for a kernel density plot in Stata is nearly identical to the “twoway hist” code above.
twoway ///
(kdensity myvariable if group==0, color(blue%30)) ///
(kdensity myvariable if group==1, color(red%30)) ///
, ///
legend(order(1 "Group==0" 2 "Group==1"))
Output:
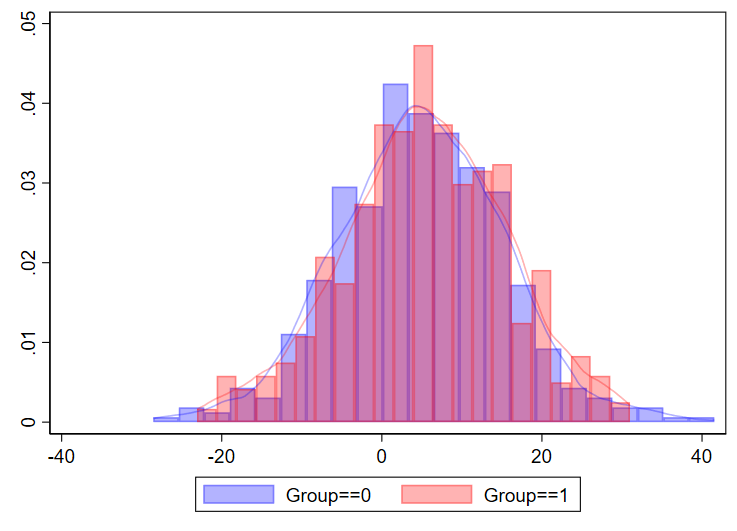
You can even combine histograms and kernel density plots!
twoway ///
(hist myvariable if group==0, color(blue%30)) ///
(hist myvariable if group==1, color(red%30)) ///
(kdensity myvariable if group==0, color(blue%30)) ///
(kdensity myvariable if group==1, color(red%30)) ///
, ///
legend(order(1 "Group==0" 2 "Group==1"))
I’ve never done this myself for a manuscript, but just showing that it’s possible.
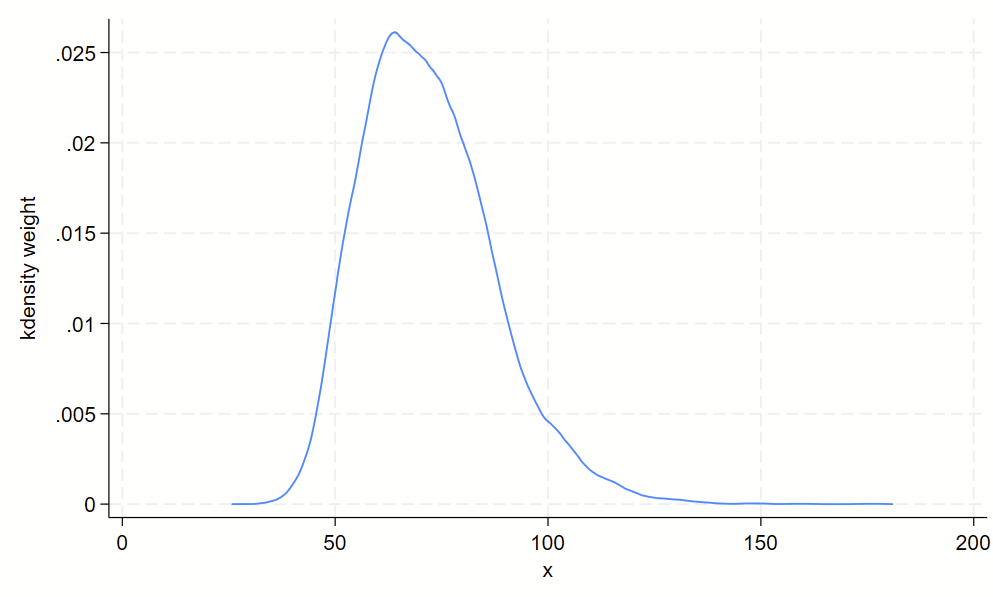
Using kdens to make kernel density plots that use pweights
You might need to make kernel density plots that use pweighting. There’s a –kdens– package that allows you to do that, which requires –moremata– to be installed. Here’s how you can make a pweighted kernel density plot with kdens.
// only need to install once:
ssc install moremata
ssc install kdens
// load nhanes demo code
webuse nhanes2f, clear
// now svyset the data and use kdens to make a weighted plot
svyset psuid [pw=finalwgt], strata(stratid)
twoway kdens weight [pw=finalwgt]
And you’ll get this!
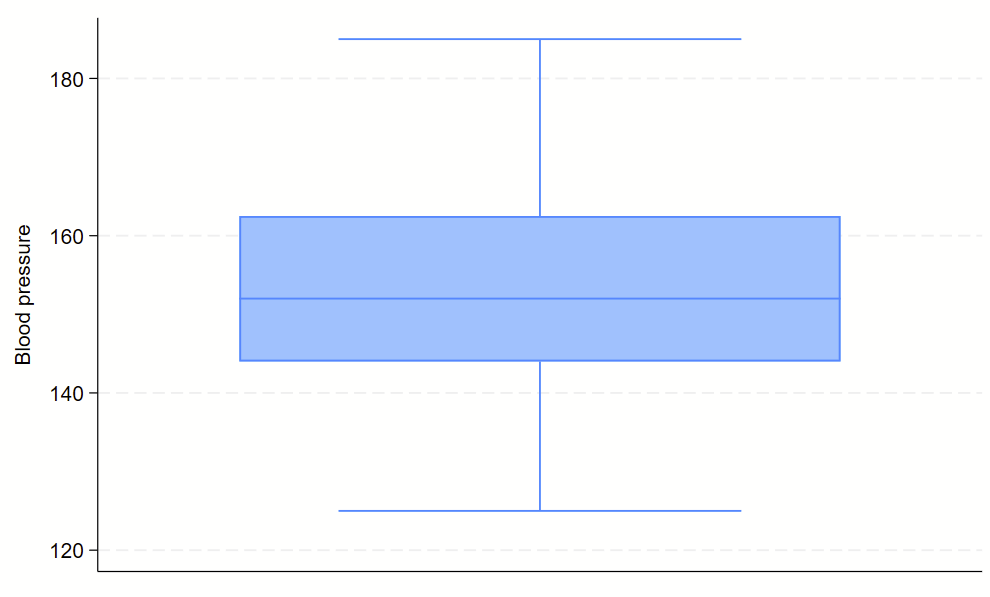
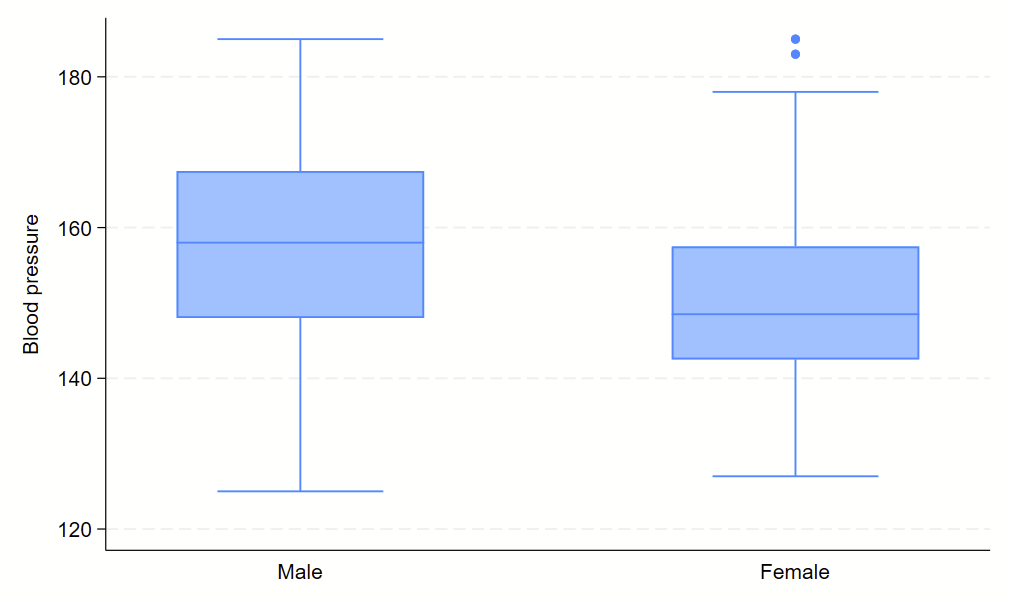
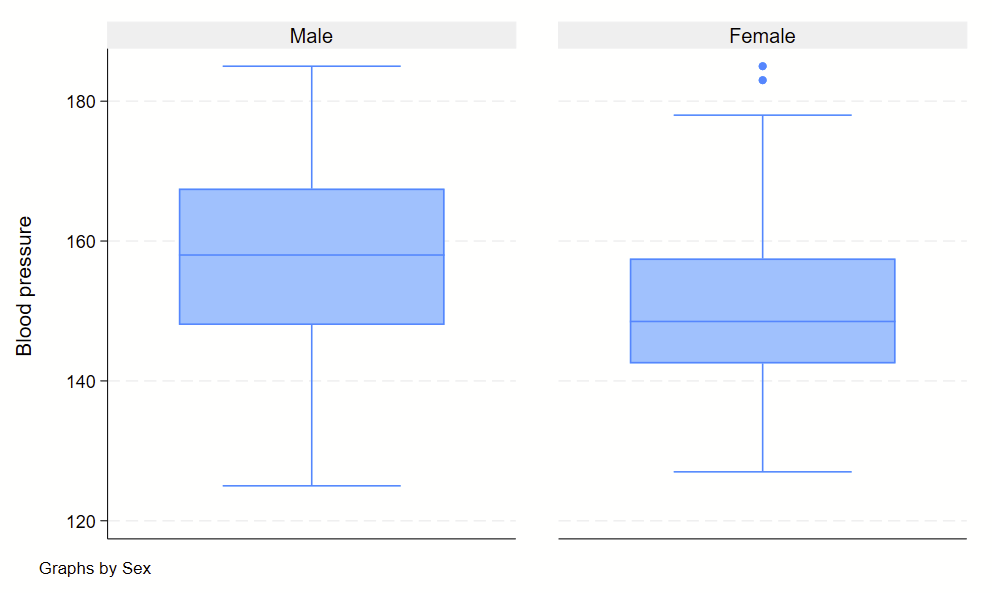
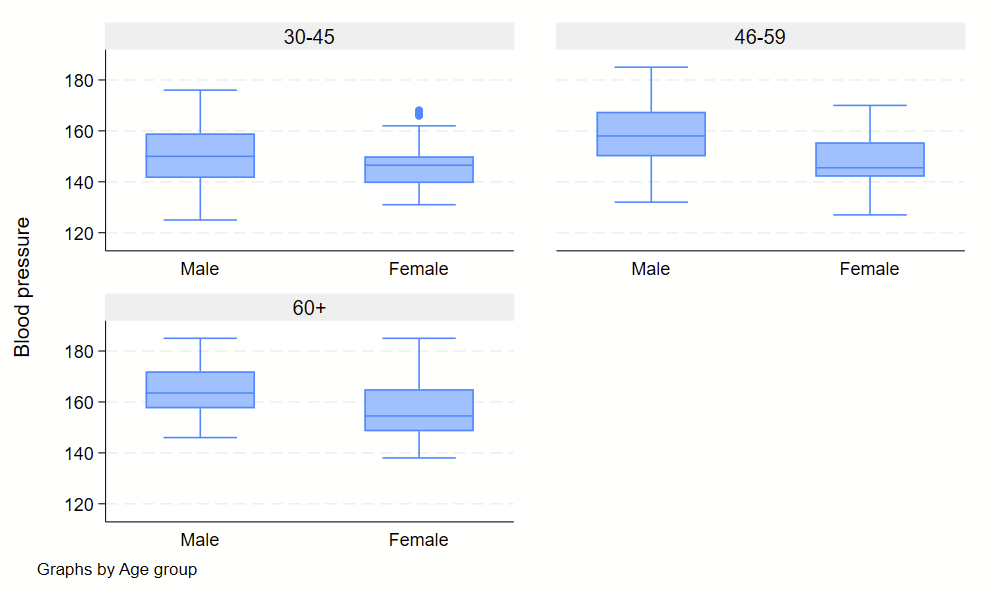
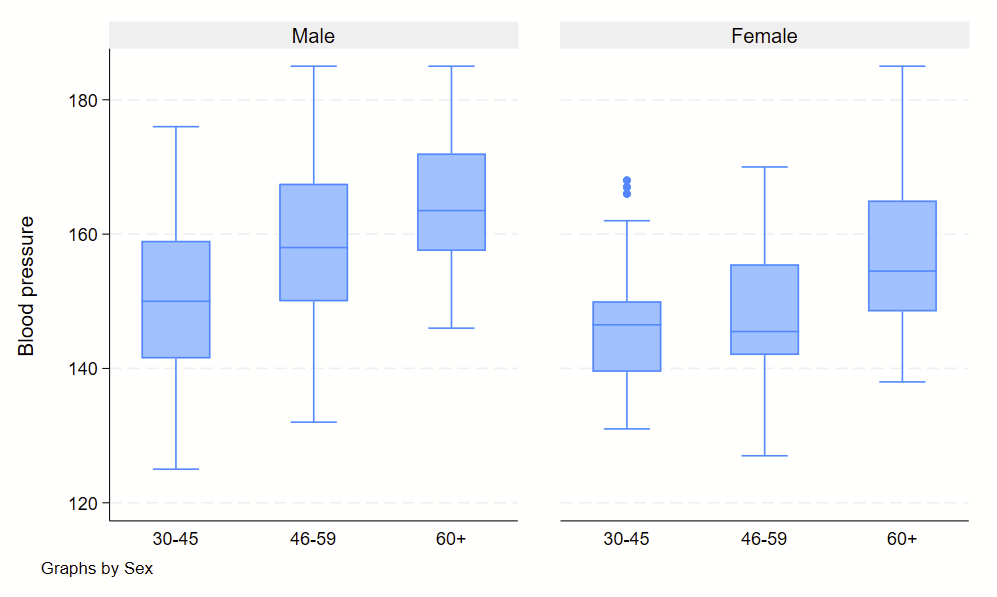
4. Boxplots
Boxplots are handy at showing distributions of multiple groups all at once. This is a nice overview of what all of the bits of the figure means. Briefly, there’s a box that is the median and IQR. There are some lines sticking out that are the upper and lower adjacent lines, which are the 75th percentile + (1.5*the width of the IQR range) and 25th percentile – (1.5*the width of the IQR range). Dots outside these ranges are the outliers.
Making boxplots is simple in stata using the –graph box– command. My one piece of advice is to be aware of the by() and over() commands since they can help you stitch together boxplots in interesting ways. Example code follows.
Tables describing the baseline characteristics of your analytical sample are ubiquitous in observational epidemiology manuscripts. They are critical to help the reader understand the study population and potential limitations of your analysis. A table characterizing baseline characteristics is so important that it’s typically the first table that appears in any observational epidemiology (or clinical trial) manuscript, so it’s commonly referred to as a “Table 1“. Table 1s are critically important because they help the readers understand internal validity of your study. If your study has poor internal validity, then your results and findings aren’t useful.
The details here are specific to prospective observational studies (e.g., cohort studies), but are generalizable to other sorts of studies (e.g., RCTs, case-control studies).
There are several variations of the Table 1, here’s how I do it.
COLUMNS: This is your exposure of interest (i.e., dependent variable). This is not the outcome of interest. There’s a few way to divvy up these columns, depending on what sort of data you have:
Continuous exposure (e.g., baseline LDL-cholesterol level): Cut this up into quantiles. I commonly use tertiles (3 groups) or quartiles (4 groups). People have very, very strong opinions about whether you use tertiles or quartiles. I don’t see much of a fuss in using either. Of note, there usually is no need to transform your data prior to splitting into quantiles. (And, log transforming continuous data that includes values of zero will replace those zeros with missing data!)
Discrete exposure:
Dichotomous/binary exposure (e.g., prevalent diabetes status as no/0 or yes/1): This is easy, column headers should be 0 or 1. Make sure to use a descriptive column header like “No prevalent diabetes” and “Prevalent diabetes” instead of numbers 0 and 1.
Ordinal exposure, not too many groups (e.g., never smoker/0, former smoker/1, current smoker/2): This is also easy, column headers should be 0, 1, or 2. Make sure to use descriptive column headers.
Ordinal exposure, a bunch of groups (e.g., extended Likert scale ranging from super unsatisfied/1 to super satisfied/7): This is a bit tricker. On one hand, there isn’t any real limitation on how wide a table can be in a software package so you could have columns 1, 2, 3, 4, 5 ,6 and 7. This is a bit unwieldy for the reader, however. I personally think it’s better to collapse really wide groupings into a few groups. Here, you could collapse all of the negative responses (1, 2 and 3), leave the neutral response as its own category (4), and collapse all of the positive responses (5, 6, and 7). Also use descriptive column headers, but also be sure to describe how you collapsed groups in the footer of the table.
Nominal exposure, not too many groups (e.g., US Census regions of Northeast, Midwest, South, and West): This is easy, just use the groups. Be thoughtful about using a consistent order of these groups throughout your manuscript.
Nominal exposure, a bunch of groups (e.g., favorite movie): As with ‘Ordinal data, a bunch of groups’ above, I would collapse these into groups that relate to each other, such as genre of movie.
(Optional) Additional first column showing “Total” summary statistics. This presents summary statistics for the entire study population as a whole, instead of by quantile or discrete groupings. I don’t see much value in these and typically don’t include them.
(Optional) Additional first column showing count of missingness for each row. This presents a count of missing values for that entire row. I think these are nice to include, but they don’t show missingness by column so are an imperfect way to show missingness. See the section below on ‘cell contents’ for alternative strategies to show missingness.
Note: Table1_mc for Stata cannot generate a “missingness” row.
(Optional, but suggest to avoid) Following P-value column that shows comparisons across rows. These have fallen out of favor for clinical trial Table 1s. I see little value of them for prospective observational studies and also avoid them.
ROWS: These include the N for each column, the range of values for continuous exposures, and baseline values. Note that the data here are from baseline.
N for each group. Make sure that these Ns add up to the expected N in your analytical population at the bottom of your inclusion flow diagram. If it doesn’t match, you’ve done something wrong.
(For continuous exposures) Range of values for your quantiles and yes I mean minimum and maximum for each quantile, not IQRs.
Medical problems as relevant to your study (eg, proportion with hypertension, diabetes, etc.)
Medical data as relevant to your study (eg, laboratory assays, details with radiological imaging, details from cardiology reports)
Suggest avoiding the outcome(s) of interest as additional rows. I think that presenting the outcomes in this table is inadequate. I prefer to have a separate table or figure dedicated to the outcome of interest that goes much more in-depth than a Table 1 does. Plus, the outcome isn’t ascertained at baseline in a prospective observational study, and describing the population at baseline is the general purpose of Table 1.
And for the love of Pete, please make sure that all covariates in your final model appear as rows. If you have a model that adjusts for Epworth Sleepiness Score, for example, make sure that fits in somewhere above.
The first column of your Table 1 will describe each row. The appearance of this row will vary based upon the type of data you have.
Overall style of row descriptions as it appears in the first column:
N row – I suggest simply using “N”, though some folks use N (upper case) to designate the entire population and n (lower case) to designate subpopulations, so perhaps you might opt to put “n”.
Continuous variables (including the row for range)– I suggest a descriptive name and the units. Eg, “Height, cm”
Discrete variables – I suggest a descriptive name alone. Some opt to put a hint to the contents of the cell here (eg, adding a percentage sign such as “Female sex, %“), but I think that is better included in the footer of the table. This will probably be determined by the specific journal you are submitting to.
Dichotomous/binary values – In this example, sex is dichotomous (male vs. female) since that’s how it has historically been collected in NIH studies. For dichotomous variables, you can include either (1) a row for ‘Male’ and a row for ‘Female’, or (2) simply a row for one of the two sexes (eg, just ‘Female’) since the other row will be the other sex.
Other discrete variables (eg, ordinal or nominal) – In this example, we will consider the nominal variable of Race. I suggest having a leading row that provides description of the following rows (eg, “Race group”) then add two spaces before each following race group so the nominal values for the race groups seem nested under the heading.
(Optional) Headings for groupings of rows – I like including bold/italicized headings for groupings of data to help keep things organized.
Here’s an example of how I think a blank table should appear:
Table 1 – Here is a descriptive title of your Table 1 followed by an asterix that leads to the footer. I suggest something like “Sociodemographics, anthropometrics, medical problems, and medical data ascertained baseline among [#] participants in [NAME OF STUDY] with [BRIEF INCLUSION CRITERIA] and without [BRIEF EXCLUSION CRITERIA] by [DESCRIPTION OF EXPOSURE LIKE ‘TERTILE OF CRP’ OR ‘PREVALENT DIABETES STATUS’]*”
(Optional) Missing, N
(Optional) Total
Exposure Variable Tertile 1
Exposure Variable Tertile 2
Exposure Variable Tertile 3
(Optional, suggest avoiding) P-value
N
Range, ng/mL
Sociodemographics
Age, y
Female sex
Race group
Black
White
Asian
Anthropometrics
Height, cm
Weight, kg
BMI, kg/m²
Medical problems
[List out here]
Medical data
[List out here]
*Footer of your Table 1. I suggest describing the appearance of the cells, eg “Range is minimum and maximum of the exposure for each quantile. Presented as mean (SD) for normally distributed and median (IQR) for skewed continuous variables. Discrete data are presented as column percents.”
Cell contents
The cell contents varies by type of variable and your goal in this table:
Simplicity as goal:
Normally distributed continuous variables: Mean (SD)
Non-normally distributed continuous variables: Median (IQR)
Discrete variables: Present column percentages. Not row percentages. For example we’ll consider “income >$75k” by tertile of CRP. A column percentage would show the % of participants in that specific quantile have an income >$75k. A row percentage would show the percentage of participants with income >$75K who were in that specific tertile.
Clarity of completeness of data as goal (would not also include “missing” column if doing this)
Continuous variables: Present as mean (SD) or median (IQR) as outlined above based upon normality, but also include an ‘n’. Example for age: “75 (6), n=455”
Note: Table1_mc in Stata cannot report an ‘n’ with continuous variables.
Dichotomous variables: Present column percentage plus ‘n’. Example for female sex: “45%, n=244”.
A word on rounding: I think there is little value on including numbers after the decimal place. I suggest aggressively rounding at the decimal for most things. For example, for BMI, I suggest showing “27 (6)” and not “26.7 (7.2)”. For things that are obtained at the decimal place, I strongly recommend reporting at the decimal. For example, BP is always measured as a whole number, so reporting out a tenth place for BP isn’t of much value. For example, systolic BP is measured as 142, 112, and 138 — not 141.8, 111.8 and 138.4. For discrete variables, I always round the proportion/percentage at the decimal, but clarify very small proportions to be “<1%" if there are any in that group, but it would round to zero or "0%" if there are none in that group.
The one exception to my aggressive “round at the decimal place” strategy is variables that are commonly reported past the decimal place, such as many laboratory values. Serum creatinine is commonly reported to the hundredths place (e.g., “0.88”), so report the summary statistic for that value to the hundredths place, like 0.78 (0.30).